MP #03: Do Proportional Electoral College Allocations Yield a More Representative Presidency?
Author
Elissa Leung
Introduction
Every four years, the US holds a presidential election, where citizens go to polling sites to cast their votes for potential presidential candidates. The way these popular votes are handled in each state have varied over time. Though, the following has remained the same:
In each of the 50 states, there are R + 2 electoral college votes (where R is the number of Representatives the state has in the US House of Representatives)
For the purposes of this assignment, we will be counting each distinct district as one Representative
States are able to allocate these ECVs however they want
The candidate that receives the majority of ECVs becomes the President
There are essentially no rules in place on how the R + 2 ECVs for each state are allocated in the Constitution. Thus, at different points in time, various states have allocated their ECVs with the following methods:
Direct allocation of ECVs by state legislature (no vote)
Allocation of all ECVs to winner of state-wide popular vote
Allocation of all ECVs to winner of nation-wide popular vote
Allocation of R ECVs to popular vote winner by congressional district + allocation of remaining 2 ECVs to the state-wide popular vote winner
Currently, 48 states use the state-wide popular vote ECV allocation method. The only two states that have diverged from this are Maine and Nebraska, which use the final option.
The goal for this project is to explore the various electoral college vote (ECV) allocation methods for the presidential elections and assess the outcomes of each election had these methods been different.
We will be using data from the MIT Election Data Science Lab1 which has collected votes from all biennial congressional races in all 50 states and the statewide presidential vote counts from 1976 to 2022. Furthermore to assist with our map data visualization, we will be utilizing the congressional and/or state shape files created by Lewis et al. (1976-2012) and the US Census Bureau (2014-2022). With this data, we hope to visualize past election outcomes and assess the fairness of various ECV allocation schemes.
Set-Up and Initial Exploration
Below are some useful packages we will need to utilize throughout our US election data analysis.
Code
# Install necessary packagesif(!require("dplyr")) install.packages("dplyr")if(!require("tidyverse")) install.packages("tidyverse")if(!require("sf")) install.packages("sf")if(!require("haven")) install.packages("haven")if(!require("DT")) install.packages("DT")if(!require("gt")) install.packages("gt")if(!require("ggplot2")) install.packages("ggplot2")if(!require("RColorBrewer")) install.packages("RColorBrewer")if(!require("stringr")) install.packages("stringr")if(!require("patchwork")) install.packages("patchwork")if(!require("gganimate")) install.packages("gganimate")if(!require("zoom")) install.packages("zoom")if(!require("gridExtra")) install.packages("gridExtra")# Load packages into Rlibrary(dplyr)library(tidyverse)library(sf)library(haven)library(DT)library(gt)library(ggplot2)library(RColorBrewer) # different color palette optionslibrary(stringr)library(patchwork) # inset plotslibrary(gganimate)library(zoom) # zoom for plotslibrary(gridExtra) # labels outside the plot
Data I: US House Election Votes from 1976 to 2022
For our analysis, we will be downloading data from the MIT Election Data Science Lab, which collects votes from all biennial congressional races in each state from 1976 to 2022 as well as the statewide presidential vote counts from 1976 to 2020. We will need to download these files from the web and read them in as follows.
Data II: Congressional Boundary Files 1976 to 2012
Next, to visualize the past election results onto a US map, we will have to download the district shapefiles for the US from 1976 to 2022. We will download the US district shape files from 1976 to 2012 from Lewis et al. automatically with the following code.
Code
# Function to download district shape zip files from Jeffrey B. Lewis, Brandon DeVine, Lincoln Pritcher, and Kenneth C. Martisget_district_file <-function(fname){ BASE_URL <-"https://cdmaps.polisci.ucla.edu/shp/" fname_ext <-paste0(fname, ".zip")if(!file.exists(fname_ext)){ FILE_URL <-paste0(BASE_URL, fname_ext)download.file(FILE_URL, destfile = fname_ext) }}# For loop to download district095 to district112 zip filesfor (i in95:112) { filename <-case_when(i <100~paste0("districts0", as.character(i)), i >=100~paste0("districts", as.character(i)))get_district_file(filename)}
Data III: Congressional Boundary Files 2014 to Present
Additionally, for more recent elections from 2014 to 2022, we can download shapefiles from the US Census Bureau. The following code will automatically download these congressional district shapefiles.
Code
# Function to download district shape zip files from US Census Bureauget_district_file_census <-function(fname, year){ BASE_URL <-paste0("https://www2.census.gov/geo/tiger/TIGER", as.character(year), "/CD/") fname_ext <-paste0(fname, ".zip")if(!file.exists(fname_ext)){ FILE_URL <-paste0(BASE_URL, fname_ext)download.file(FILE_URL, destfile = fname_ext) }}# For loop to download congressional shapefiles (zip files) from 2014-2022for (i in2014:2022) { filename <-case_when(i <2016~paste0("tl_", as.character(i), "_us_cd114"), i >=2016& i <2018~paste0("tl_", as.character(i), "_us_cd115"), i >2017~paste0("tl_", as.character(i), "_us_cd116"))get_district_file_census(filename, i)}
Additionally for ease of plotting state geometries later in the project, the below code will download the state shape file from 2020 (the most recent presidential election that we have access to).
Code
# Function to download district shape zip files from US Census Bureauget_state_file_census <-function(fname, year){ BASE_URL <-paste0("https://www2.census.gov/geo/tiger/TIGER", as.character(year), "/STATE/") fname_ext <-paste0(fname, ".zip")if(!file.exists(fname_ext)){ FILE_URL <-paste0(BASE_URL, fname_ext)download.file(FILE_URL, destfile = fname_ext) }}# Download state shapefiles zip folder from 2020get_state_file_census("tl_2020_us_state", 2020)
Initial Exploration of Vote Count Data
Before beginning any specific deep-dive analysis, it is important to conduct some preliminary exploration of our data sets to understand the information that we have.
Preliminary Questions
Below are some preliminary questions we will answer as an initial exploration of our data
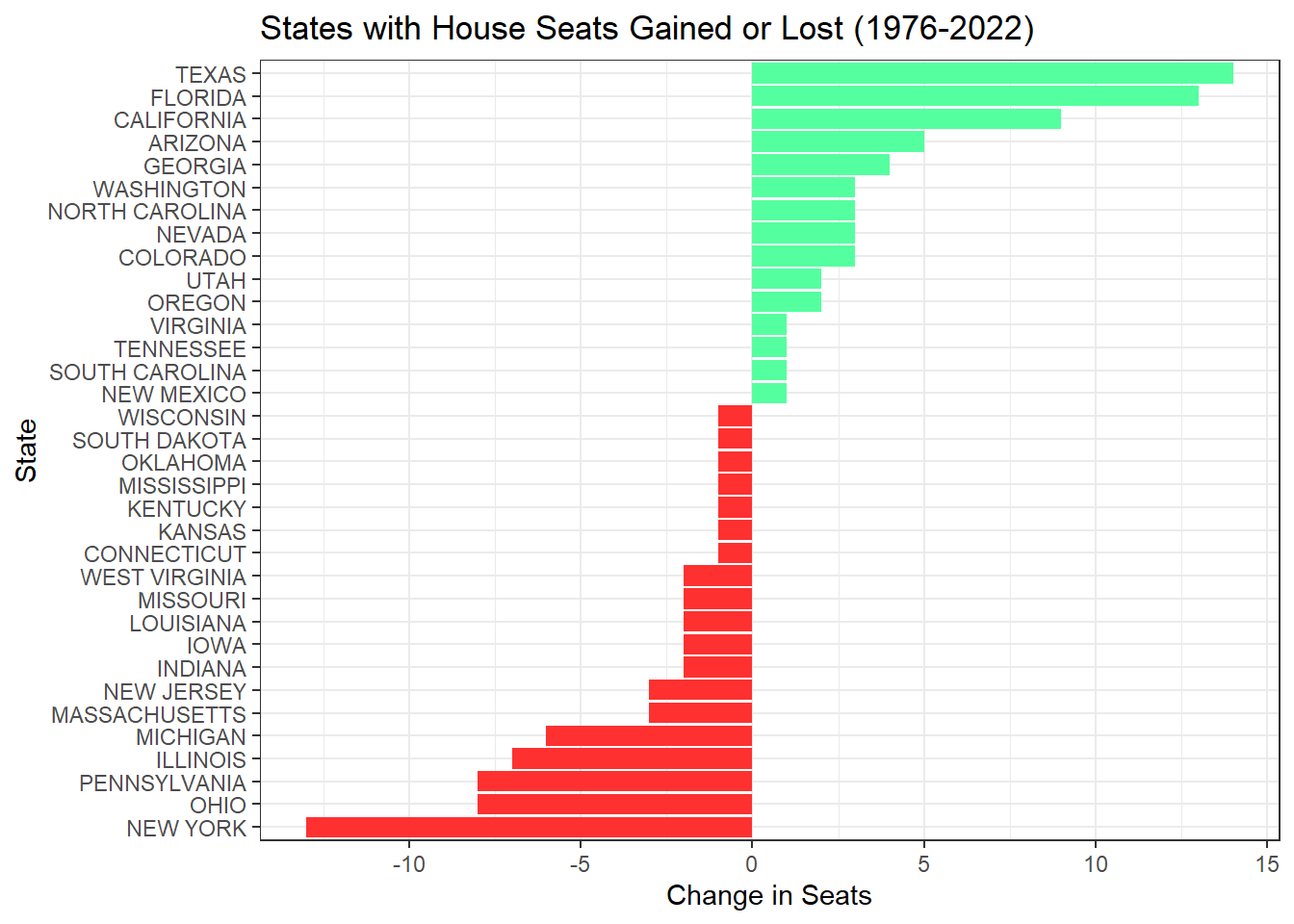
Which states have gained and lost the most seats in the US House of Representatives between 1976 and 2022?
New York State has a unique “fusion” voting system where one candidate can appear on multiple “lines” on the ballot and their vote counts are totaled. For instance, in 2022, Jerrold Nadler appeared on both the Democrat and Working Families party lines for NYS’ 12th Congressional District. He received 200,890 votes total (184,872 as a Democrat and 16,018 as WFP), easily defeating Michael Zumbluskas, who received 44,173 votes across three party lines (Republican, Conservative, and Parent). Are there any elections in our data where the election would have had a different outcome if the “fusion” system was not used and candidates only received the votes they received from their “major party line” (Democrat or Republican) and not their total number of votes across all lines?
Do presidential candidates tend to run ahead of or run behind congressional candidates in the same state? That is, does a Democratic candidate for president tend to get more votes in a given state than all Democratic congressional candidates in the same state? Does this trend differ over time? Does it differ across states or across parties? Are any presidents particularly more or less popular than their co-partisans?
Question 1: Which states have gained and lost the most seats in the US House of Representatives between 1976 and 2022?
First, we would like to take a look at the change in US House seats from 1976 to 2022, to determine if there are any significant changes. There are a total of 435 members of the House of Representatives, each state is allowed a specific number of representatives based on their population size. Over time, certain states have gained and/or lost seats based on population changes. Since the US House seats directly impact the number of electoral college votes a state receives, this is an important metric to take a look at for our analysis later.
Code
# Data frame with the difference in seat changes from 1976 to 2022seat_change_1976_2022 <- house_1976_2022 |>select(c(year, state, district)) |>unique() |>group_by(year, state) |>summarize(total =n()) |>filter(year ==1976| year ==2022) |>pivot_wider(names_from = year, values_from = total) |>mutate(difference =`2022`-`1976`,positive = (difference >=0))# States with no changeno_change <- seat_change_1976_2022 |>filter(difference ==0) |>summarize(total =n()) |>pull(total)no_change_seats <- seat_change_1976_2022 |>filter(difference ==0) |>pull(state) |>c()# States that gained seatsgain_seats <- seat_change_1976_2022 |>filter(difference >0) |>summarize(total =n()) |>pull(total)# States that lost seatslost_seats <- seat_change_1976_2022 |>filter(difference <0) |>summarize(total =n()) |>pull(total)# State that gained the most seatsgained_most_seats <- seat_change_1976_2022 |>slice_max(difference, n =1) |>pull(difference)# State that lost the most seatslost_most_seats <- seat_change_1976_2022 |>slice_min(difference, n =1) |>mutate(lost =-difference) |>pull(lost)# Plot of all the states and their respective seat changes from 1976 to 2022seat_change_1976_2022 |>filter(difference !=0) |>ggplot(aes(x =reorder(state, difference), y = difference)) +geom_bar(aes(fill = positive), stat ="identity", show.legend =FALSE) +labs(title ="States with House Seats Gained or Lost (1976-2022)",x ="State",y ="Change in Seats") +coord_flip() +scale_fill_manual(values =c("TRUE"="seagreen1", "FALSE"="firebrick1")) +theme_bw()
After gathering the house seat change from 1976 to 2022, I found that 16 states had no seat change (Alabama, Alaska, Arkansas, Delaware, Hawaii, Idaho, Maine, Maryland, Minnesota, Montana, Nebraska, New Hampshire, North Dakota, Rhode Island, Vermont, Wyoming), while 34 states did. Of these 34 states, 15 states gained seats while 19 states lost seats. Texas gained the most seats from 1976 with 14 gained seats. While New York lost the most seats from 1976 with 13 lost seats.
Question 2: New York State has a unique “fusion” voting system where one candidate can appear on multiple “lines” on the ballot and their vote counts are totaled. For instance, in 2022, Jerrold Nadler appeared on both the Democrat and Working Families party lines for NYS’ 12th Congressional District. He received 200,890 votes total (184,872 as a Democrat and 16,018 as WFP), easily defeating Michael Zumbluskas, who received 44,173 votes across three party lines (Republican, Conservative, and Parent).
Are there any elections in our data where the election would have had a different outcome if the “fusion” system was not used and candidates only received the votes they received from their “major party line” (Democrat or Republican) and not their total number of votes across all lines?
The “fusion” voting system allows candidates that have their name appear on multiple party lines on the ballot to have their votes counted under one total. We will take a look at whether the fusion voting system creates a substantial change in candidates’ success. We will do so by taking a look at election outcomes with and without the fusion voting system.
From the data table below, we find that there were 24 instances when election outcomes differed between the fusion voting system and the single party system. Almost all of these outcomes came from New York elections, with only one from Connecticut in 1992.
Code
# Data frame with the highest votes for each years' election per state and district (without fusion) and the candidates that would have wonwinner_no_fusion_votes <- house_1976_2022 |>group_by(year, state, district, candidate, party) |>summarize(party_votes =sum(candidatevotes)) |>ungroup() |>group_by(year, state, district) |>filter(party_votes ==max(party_votes)) |>ungroup() |>select(c(year, state, district, candidate))# Data frame with the highest votes for each years' election per state and district (with fusion) and the candidates that wonwinner_fusion_votes <- house_1976_2022 |>group_by(year, state, district, candidate) |>summarize(candidate_total =sum(candidatevotes)) |>ungroup() |>group_by(year, state, district) |>filter(candidate_total ==max(candidate_total)) |>ungroup() |>select(c(year, state, district, candidate))# Data frame combining above two data tables to compare winners with and without fusioncomparison_winner <-left_join(winner_fusion_votes, winner_no_fusion_votes, by =c("year", "state", "district")) |>rename(winner_fusion = candidate.x,winner_no_fusion = candidate.y) |>mutate(same_winner = (winner_fusion == winner_no_fusion)) |>filter(same_winner ==FALSE)# Display a DT() data table of the elections that would've been different without the fusion voting systemcomparison_winner_df <- comparison_winner |>select(c('year', 'state', 'district', 'winner_fusion', 'winner_no_fusion'))DT::datatable(setNames(comparison_winner_df, c("Year", "State", "District", "Fusion Winner", "No Fusion Winner")), caption ="Table 1: Differences in House Seat Winners with Fusion and Without Fusion",rownames =FALSE,options =list(pageLength =10))
Question 3: Do presidential candidates tend to run ahead of or run behind congressional candidates in the same state? That is, does a Democratic candidate for president tend to get more votes in a given state than all Democratic congressional candidates in the same state?
Does this trend differ over time? Does it differ across states or across parties? Are any presidents particularly more or less popular than their co-partisans?
Lastly, we would like to explore whether the total presidential candidate votes per party exceeds or falls below the total votes of all of their party’s congressional candidates per state.
Below is the data frame comparing the difference between presidential candidate votes versus the total votes of their co-partisans per state.
Code
# Data frame counting total votes for each party in each state from house datahouse_party_votes_per_state <- house_1976_2022 |>group_by(year, state, party) |>summarize(house_party_votes =sum(candidatevotes))# Data frame counting total votes for each party in each state from president datapresident_party_votes_per_state <- president_1976_2020 |>filter(writein ==FALSE) |># otherwise will have candidates that weren't originally on the ballotselect(year, state, party_detailed, candidate, candidatevotes) |>rename(party = party_detailed)# Data frame combining president and house data sets to compare total votes# Filtered for the 2 main parties: Democrat and Republicanvote_comparison_president_house <-left_join(president_party_votes_per_state, house_party_votes_per_state,by =c('year', 'state', 'party')) |>rename(presidential_candidate = candidate,president_candidatevotes = candidatevotes) |>drop_na(house_party_votes) |>filter(party %in%c("DEMOCRAT", "REPUBLICAN")) |>mutate(president_more = (president_candidatevotes > house_party_votes),diff_p_h = president_candidatevotes - house_party_votes) |>filter(presidential_candidate !="") # one record has an empty string# Data frame output: showing the difference in votesvote_comparison_final <- vote_comparison_president_house |>select(year, state, party, presidential_candidate, diff_p_h)DT::datatable(setNames(vote_comparison_final, c("Year", "State", "Party", "Presidential Candidate", "Difference in Votes")), caption ="Table 2: Difference in Presidential Votes vs Co-Partisans per State per Election Year",rownames =FALSE,options =list(pageLength =10))
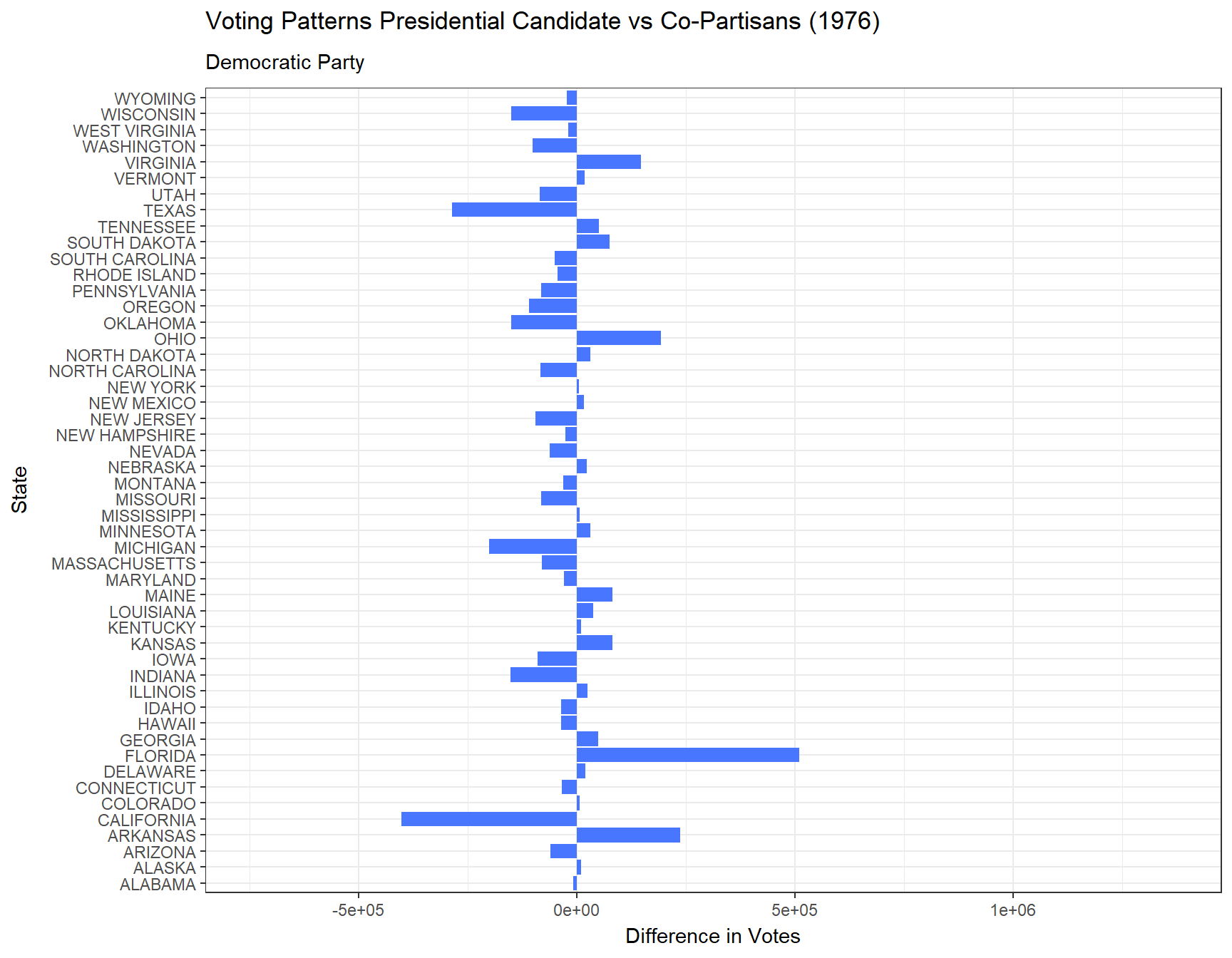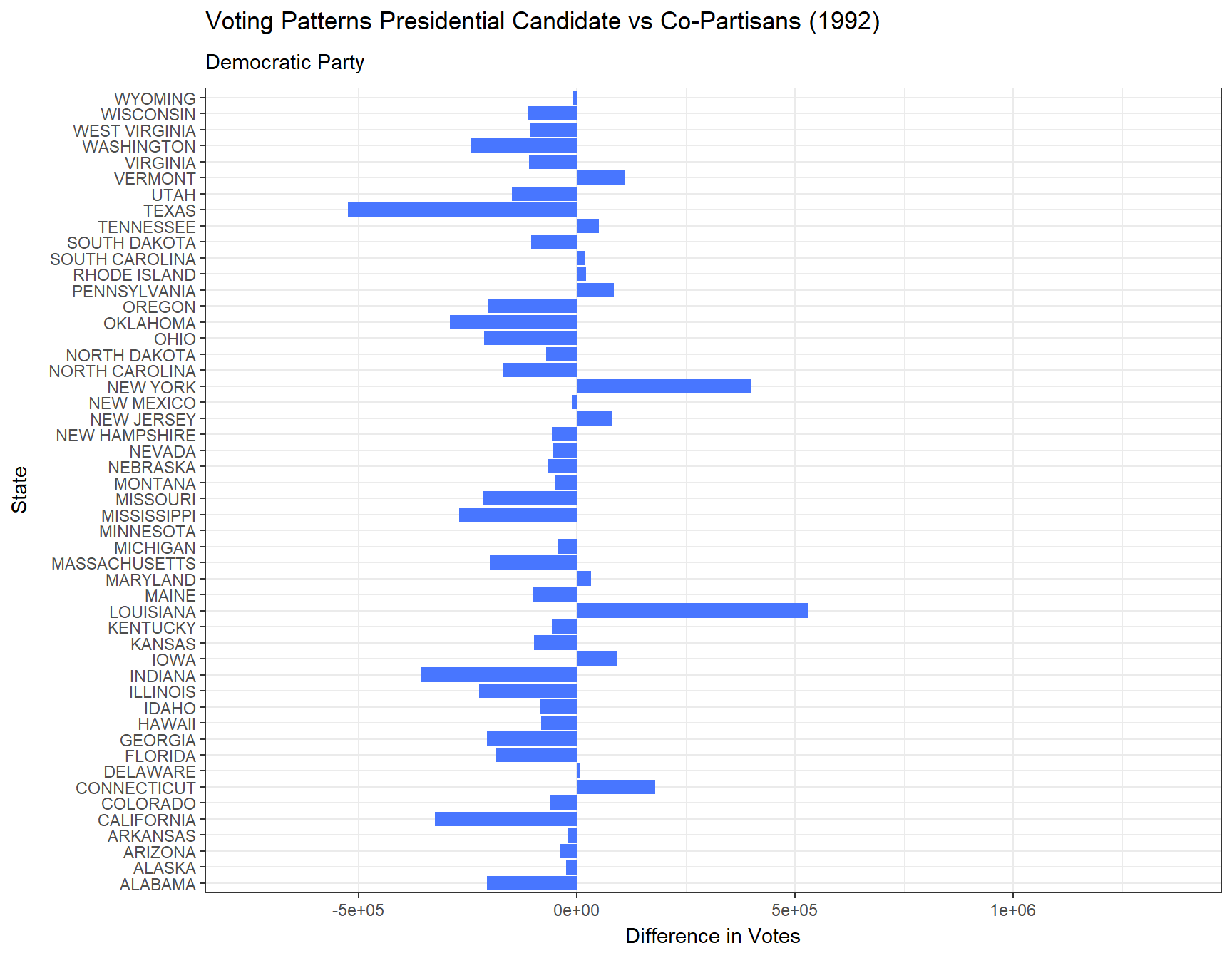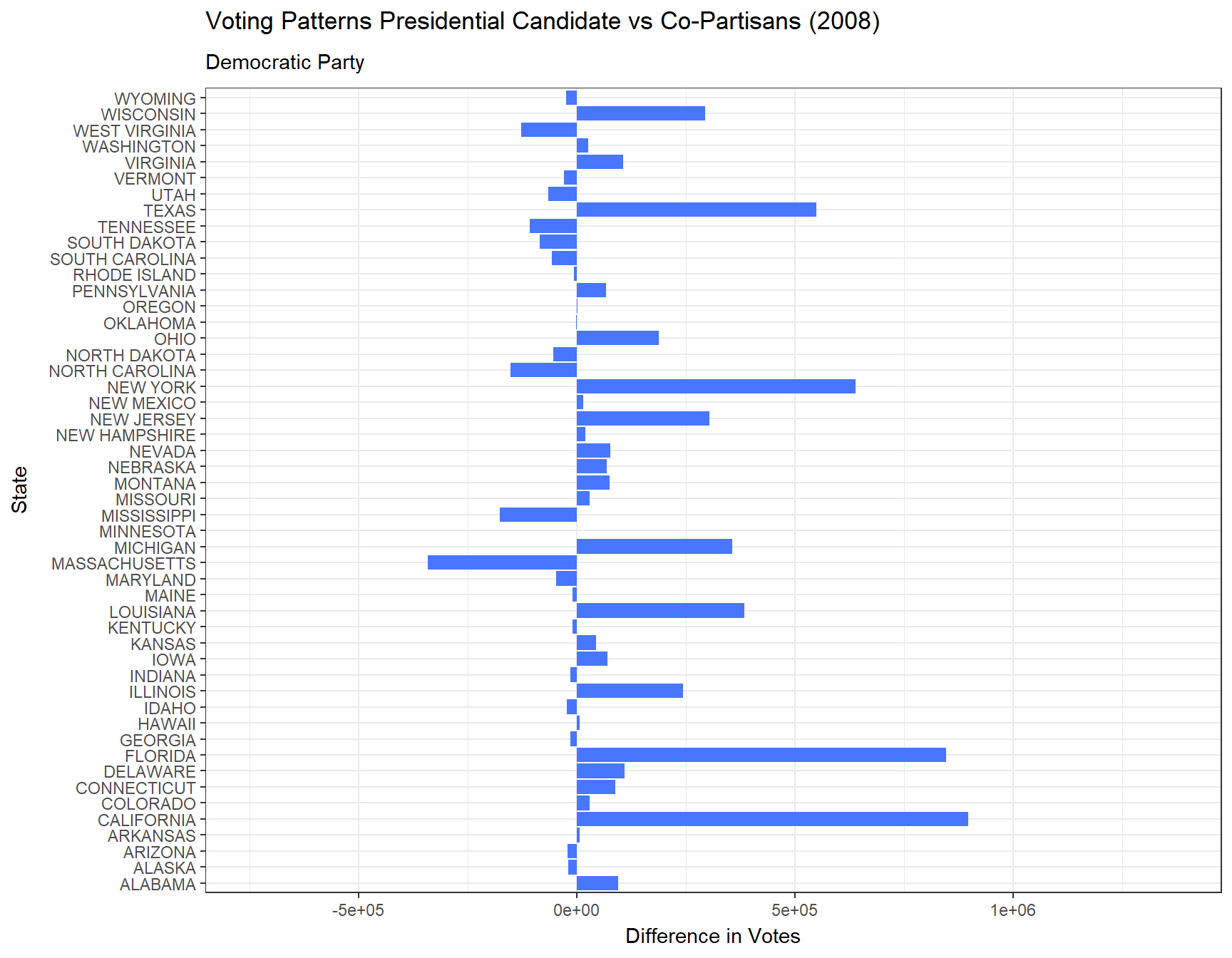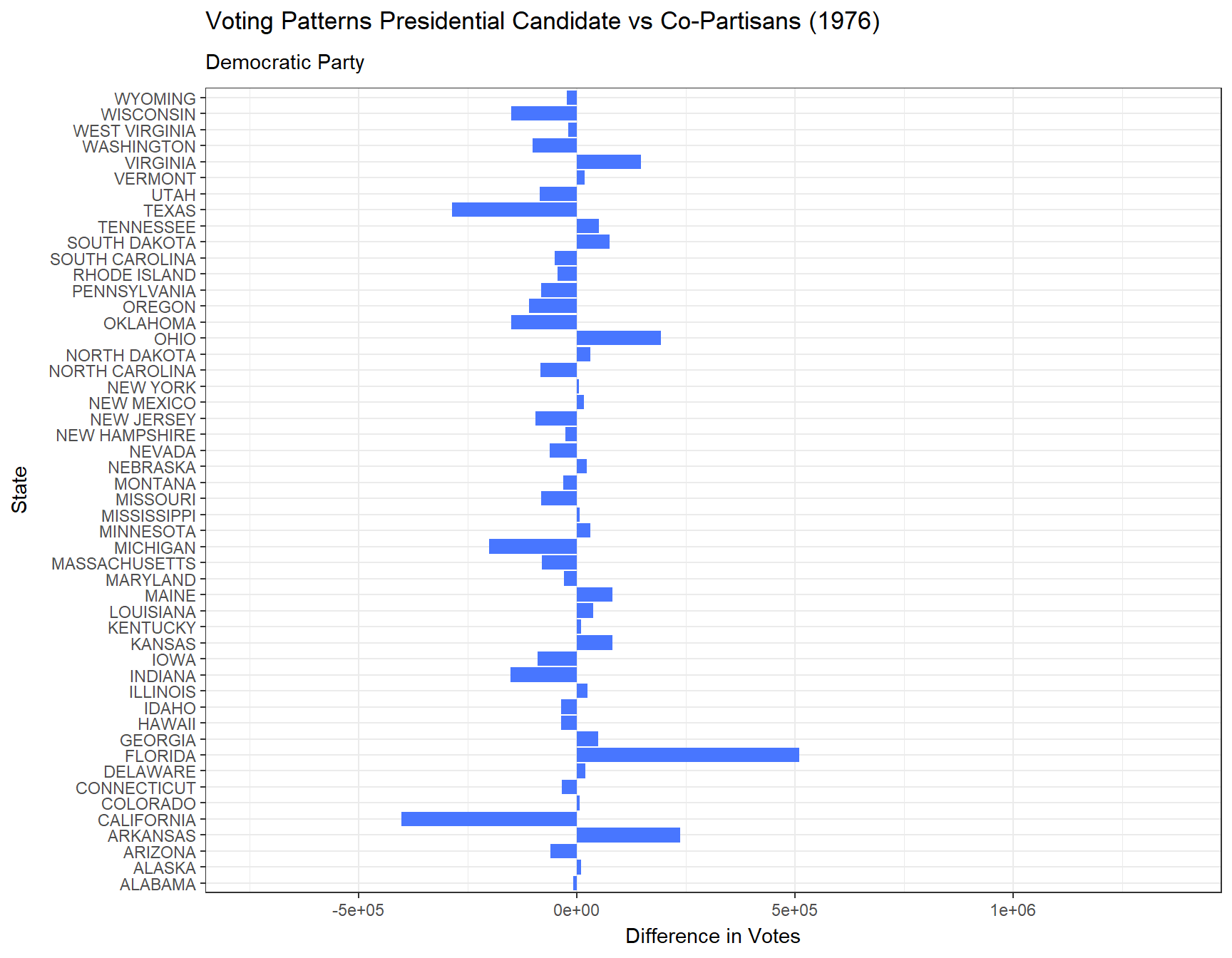
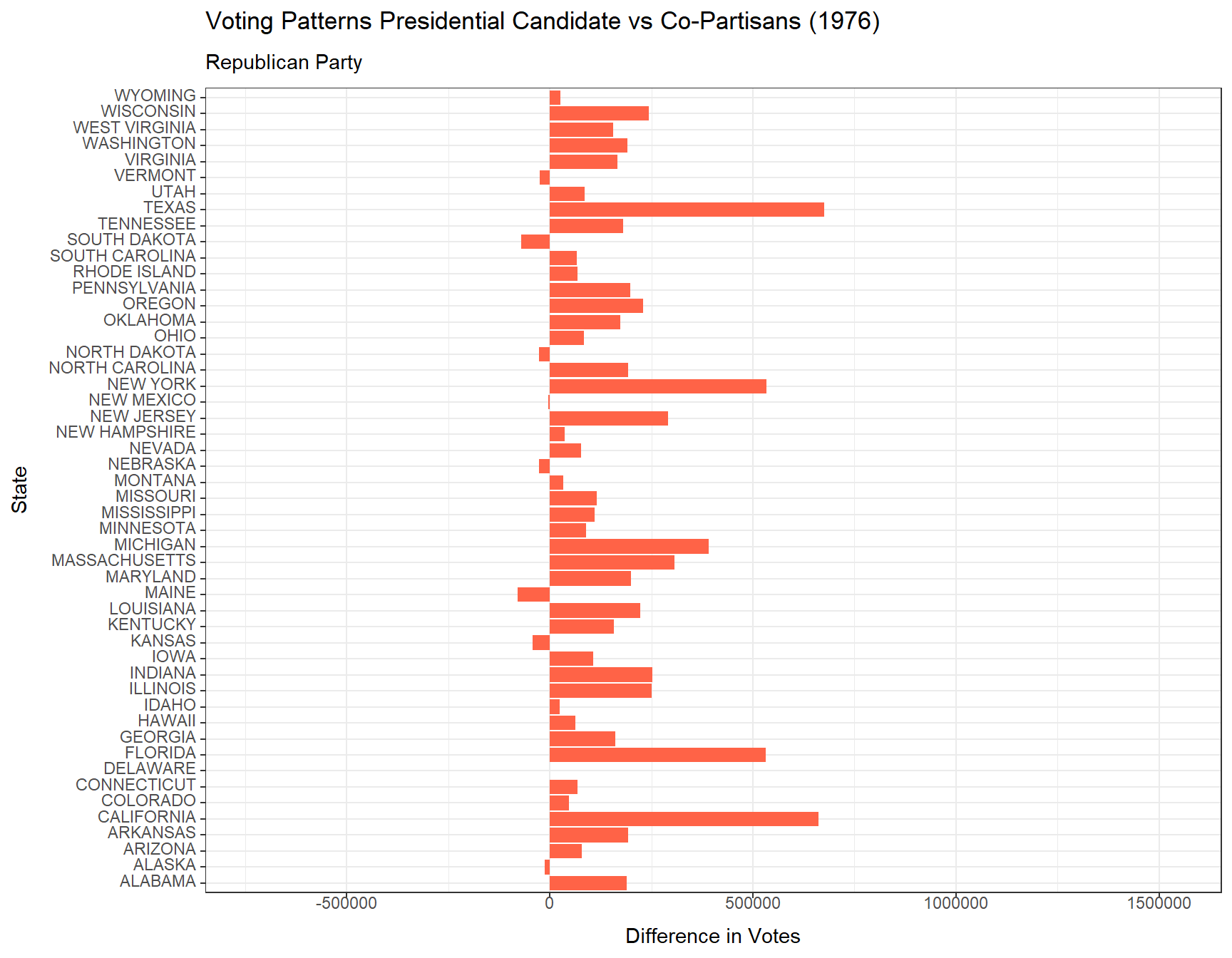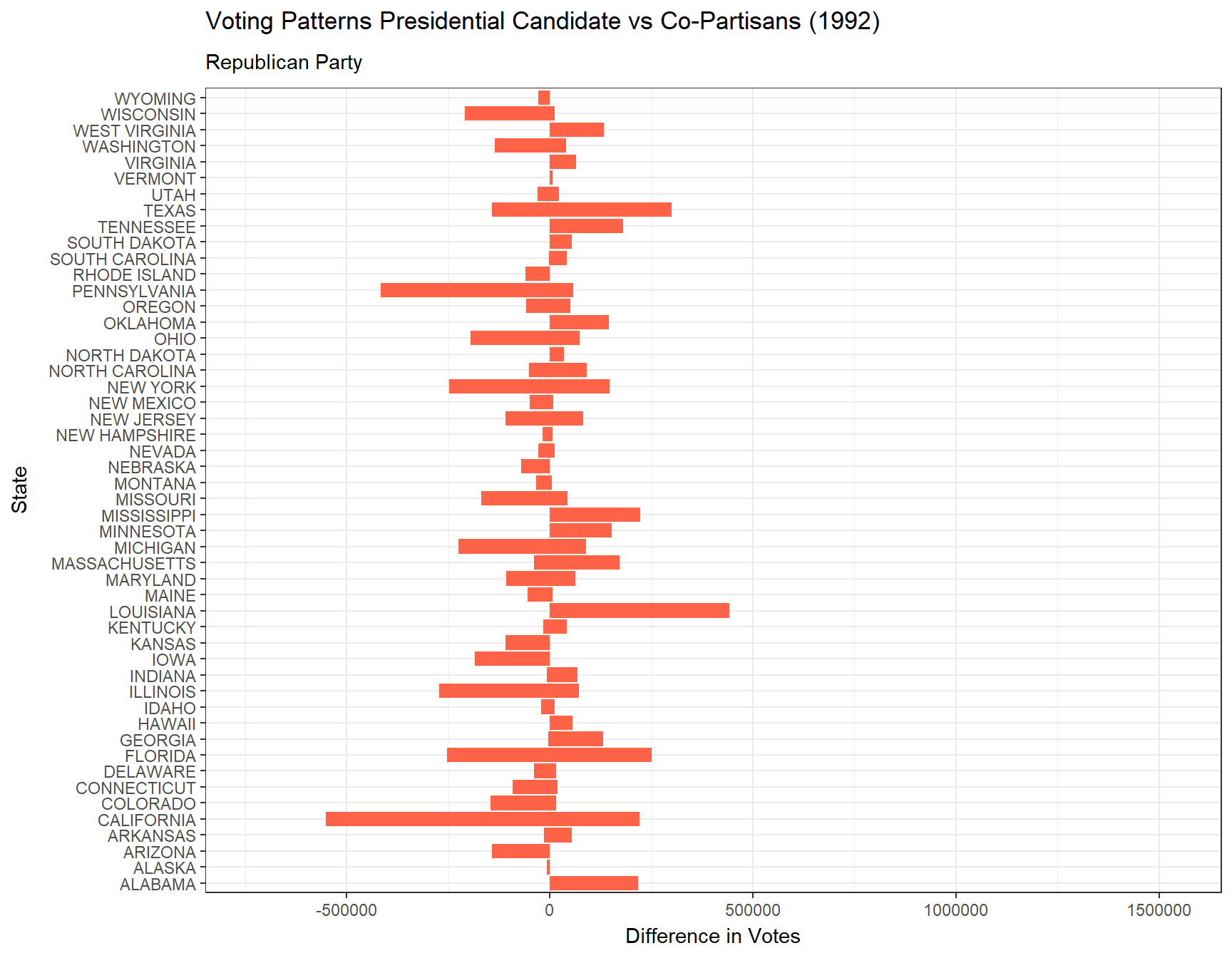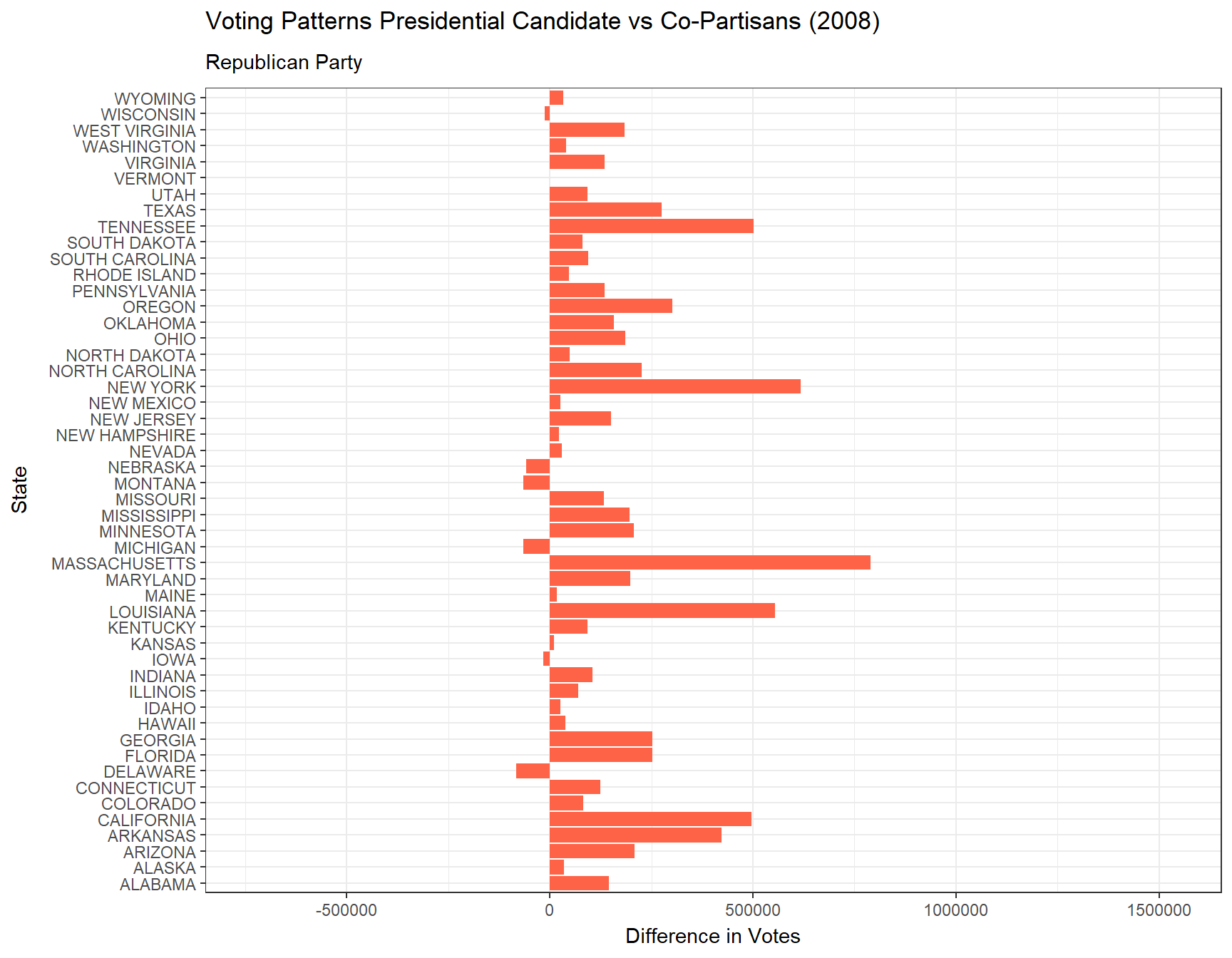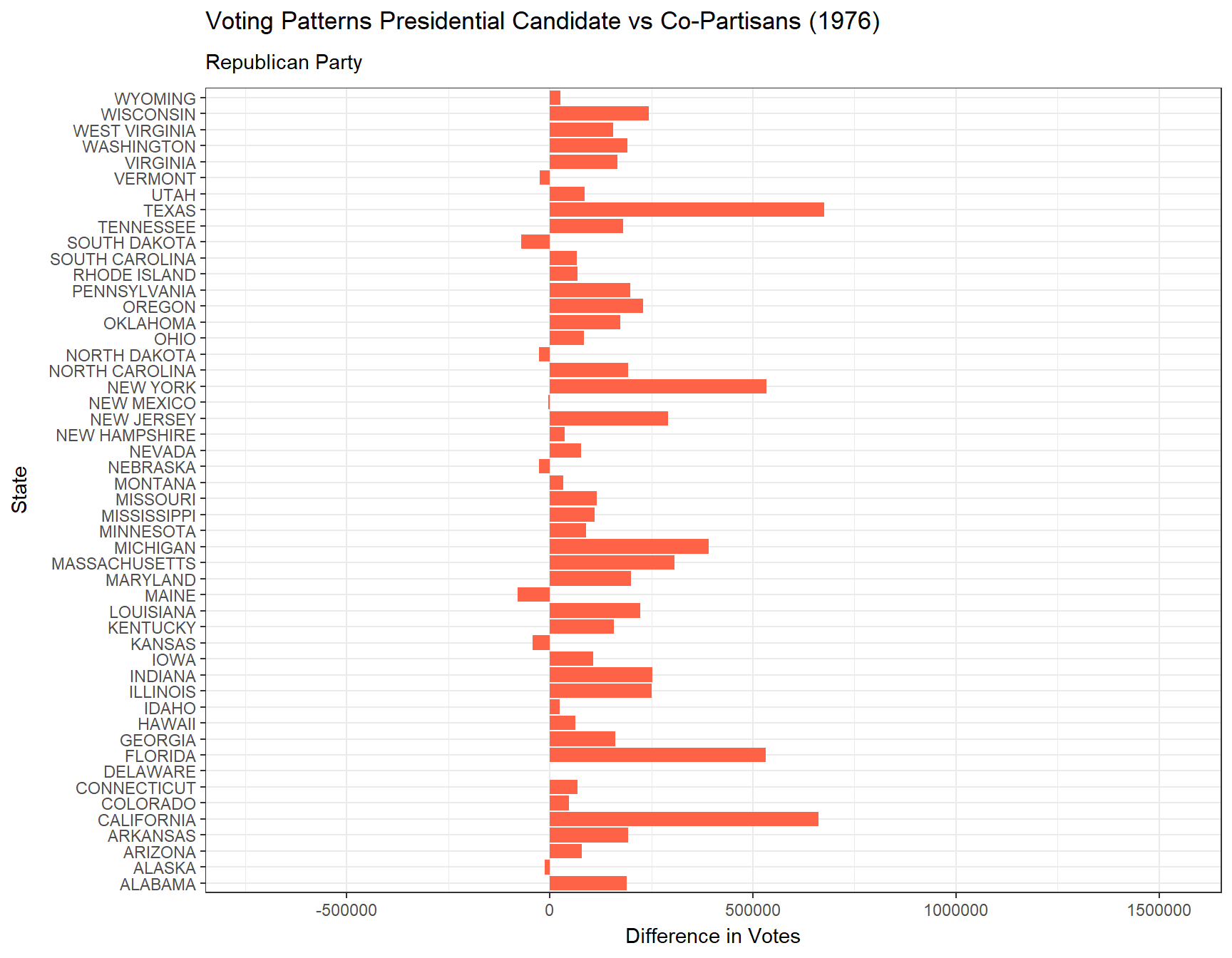
Additionally, below are animated bar plots transitioning between election years demonstrating the change in amounts of votes for the president versus their co-partisans across all 50 states and the District of Columbia from 1976 to 2020. We use blue to represent the Democratic Party and red to represent the Republican Party.
Code
# Animated plot showing the difference between presidential votes versus house votes each year in each state for the Democratic Partydem <- vote_comparison_president_house |>filter(party =="DEMOCRAT") |>ggplot(aes(x = state, y = diff_p_h)) +geom_bar(stat ="identity", fill ="royalblue1") +coord_flip() +transition_states(year) +theme_bw() +labs(title ="Voting Patterns Presidential Candidate vs Co-Partisans ({closest_state})",subtitle ="Democratic Party",x ="State",y ="Difference in Votes")animate(dem)
Code
# Animated plot showing the difference between presidential votes versus house votes each year in each state for the Democratic Partyrep <- vote_comparison_president_house |>filter(party =="REPUBLICAN") |>ggplot(aes(x = state, y = diff_p_h)) +geom_bar(stat ="identity", fill ="tomato") +coord_flip() +transition_states(year) +theme_bw() +labs(title ="Voting Patterns Presidential Candidate vs Co-Partisans ({closest_state})",subtitle ="Republican Party",x ="State",y ="Difference in Votes")animate(rep)
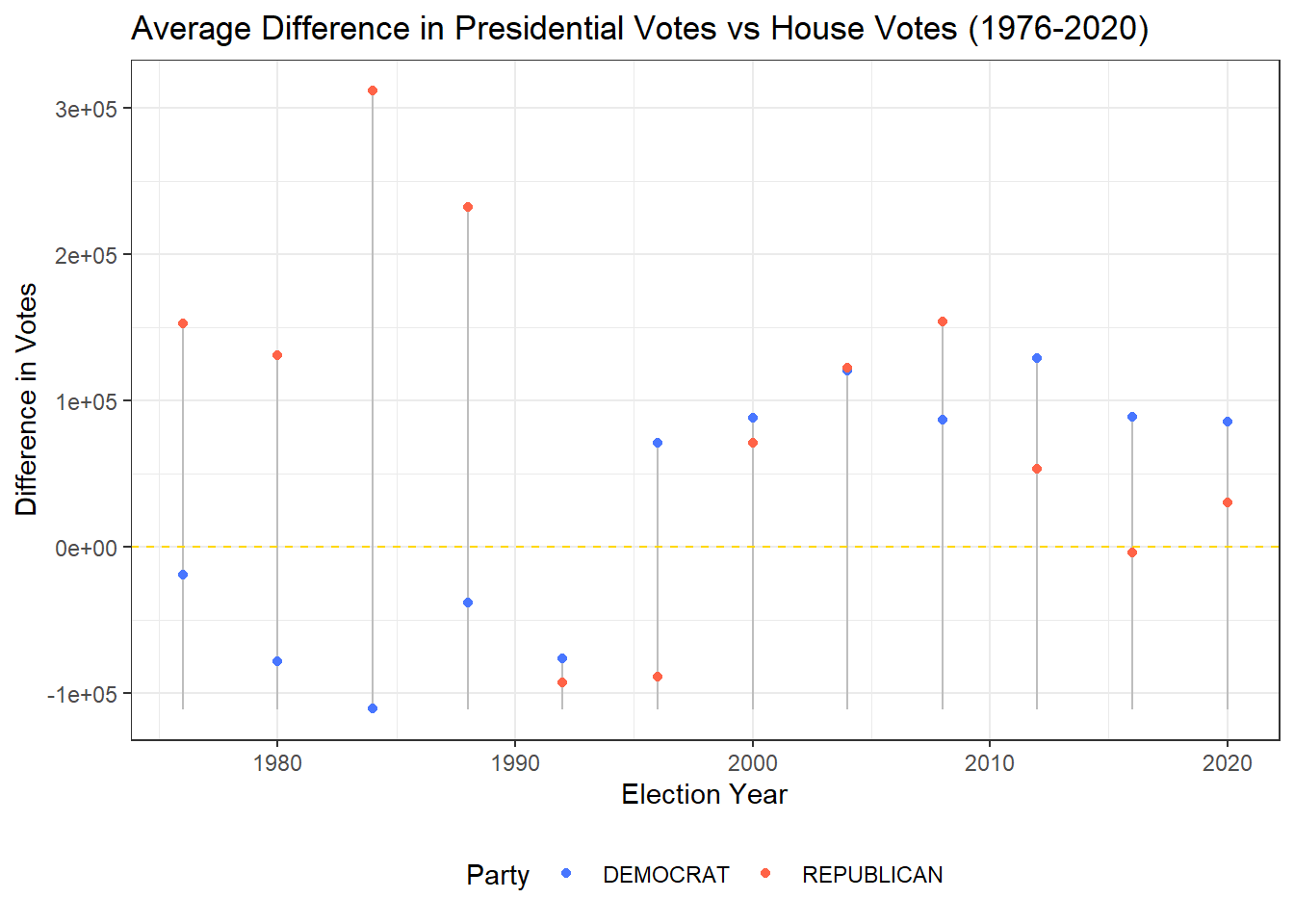
To get a more general view of this data, we take the average difference among all states for each election year and compare these changes over time for the Republican Party versus the Democratic Party. Below is a dumbbell plot examining these changes over time, the yellow dashed line indicates where on average the difference between presidential votes and the party’s congressional district votes would have been 0 (no difference).
Code
# Average difference among all 50 states + DC between presidential votes and house votes in each election yearaverage_vote_comparison_president_house <- vote_comparison_president_house |>group_by(year, party, presidential_candidate) |>summarize(average_diff =mean(diff_p_h)) |>ungroup()average_vote_comparison_president_house |>slice_min(average_diff) |>pull(average_diff)
[1] -110593.7
Code
# Graph the average change over time with a dumbbell plotaverage_vote_comparison_president_house |>ggplot(aes(x = year, y = average_diff, color = party)) +geom_segment(aes(xend = year, yend =-111000), color ="grey") +geom_point(aes(color = party)) +geom_hline(linetype ="dashed", color ="gold", yintercept =0) +scale_color_manual(values =c("DEMOCRAT"="royalblue1", "REPUBLICAN"="tomato"),name ="Party") +theme_bw() +theme(legend.position ="bottom") +labs(title ="Average Difference in Presidential Votes vs House Votes (1976-2020)",x ="Election Year",y ="Difference in Votes")
From our plot above, we find that the Democratic Party until 1996 experienced on average less votes for the presidential candidate than its co-partisans did across the 50 states and DC. While the Republican Party only saw a drop in its presidential elections in 1992, 1996, and 2016. In more recent years, it seems that for both parties, the presidential candidate generally has been more popular than its co-partisans.
Importing and Plotting Shape File Data
Below is the code used to read in the shape files from the zip archives we downloaded earlier, this will automatically read in only the shape file (shp) from each of these archives.
Code
# For loop loading all the SHP files from district 95 to 112 from Lewis et al.for (i in95:112) { td <-tempdir(); filename <-case_when(i <100~paste0("districts0", as.character(i)), i >=100~paste0("districts", as.character(i))) zip_contents <-unzip(paste0(filename, ".zip"), exdir = td) fname_shp <- zip_contents[grepl("shp$", zip_contents)]assign(paste0("districts_", as.character(i), "_sf"), read_sf(fname_shp))}# For loop loading all the Tiger/Line SHP files from US Census Bureau (2014 to 2022)for (i in2014:2022) { td <-tempdir(); filename <-case_when(i <2016~paste0("tl_", as.character(i), "_us_cd114"), i >=2016& i <2018~paste0("tl_", as.character(i), "_us_cd115"), i >2017~paste0("tl_", as.character(i), "_us_cd116")) zip_contents <-unzip(paste0(filename, ".zip"), exdir = td) fname_shp <- zip_contents[grepl("shp$", zip_contents)]assign(paste0("t1_", as.character(i), "_sf"), read_sf(fname_shp))}# Loading the state shape file for 2020td <-tempdir(); filename <-"tl_2020_us_state"zip_contents <-unzip(paste0(filename, ".zip"), exdir = td)fname_shp <- zip_contents[grepl("shp$", zip_contents)]assign(paste0("state_2020_sf"), read_sf(fname_shp))
Choropleth Visualization of the 2000 Presidential Election Electoral College Results
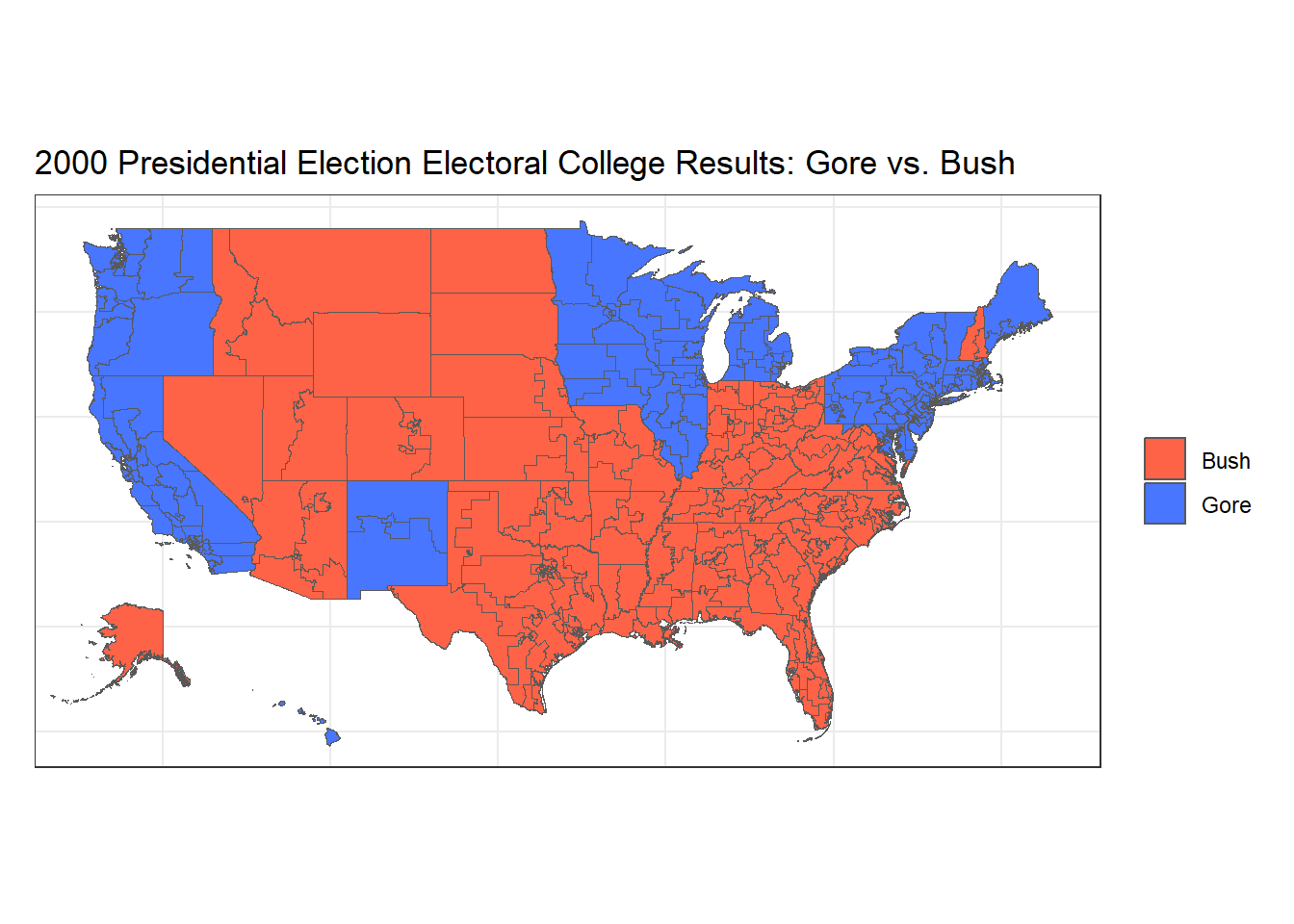
Typically, during and immediately after election day, we often see choropleth maps depicting the voting results of each state in real time. Next, we would like to recreate one of these choropleth maps for the 2000 election between Al Gore and George W. Bush. In this map, we will use the traditional blue color for the Democratic candidate, Al Gore, and red color to represent the Republican candidate, George W. Bush.
Code
# Data frame filtering out only for the winner of each state in the 2000 electionwinner_election_2000 <- president_1976_2020 |>filter(year ==2000) |>filter(party_simplified %in%c("DEMOCRAT", "REPUBLICAN")) |>group_by(state) |>mutate(most_votes =max(candidatevotes)) |>ungroup() |>mutate(win = (candidatevotes == most_votes),winner =case_when(win ==TRUE~ candidate)) |>drop_na(winner)
Using the district 107 shape file from the 2000 election, we get the plot below, where each state is colored by the party that won the most votes in the state. Since we used a district shape file to visualize the election outcome, we can also see the various districts that certain states divide into.
For easier viewing, I decided to inset Hawaii and Alaska instead of plotting them at their true map locations. Below is the code to plot the US states on the mainland (everything excluding Alaska and Hawaii).
Code
# Selecting only state and party_simplified columns to simplify when joining with sfstate_color_2000_district <- winner_election_2000 |>select(state, candidate, party_simplified) |>mutate(candidate_last =case_when(candidate =="BUSH, GEORGE W."~"Bush", candidate =="GORE, AL"~"Gore")) |>mutate(state =str_to_title(state))# Filtering only for states in the mainland so our plot isn't squishedmainland_district <- districts_107_sf |>filter(STATENAME !="Alaska"& STATENAME !="Hawaii")# Merging the two tables so we know which party won the election for each statemainland_colors_district <-left_join(mainland_district, state_color_2000_district, join_by("STATENAME"=="state"))# Plot of mainland with colors corresponding to the parties (Democrat = Blue, Republican = Red)mainland_plot_district <- mainland_colors_district |>ggplot(aes(geometry = geometry,fill = candidate_last)) +geom_sf() +scale_fill_manual(values =c("Gore"="royalblue1", "Bush"="tomato")) +theme_bw() +theme(legend.title =element_blank(),axis.title.x=element_blank(),axis.text.x=element_blank(),axis.ticks.x=element_blank(),axis.title.y=element_blank(),axis.text.y=element_blank(),axis.ticks.y=element_blank()) +labs(title ="2000 Presidential Election Electoral College Results: Gore vs. Bush")
Here is the code which plots for the remaining two states: Hawaii and Alaska.
Code
# Filtering only for Alaskaalaska_district <- districts_107_sf |>filter(STATENAME =="Alaska")# Merging the two tables (alaska and state_color_2000) so we know which party won the election for Alaskaalaska_colors_district <-left_join(alaska_district, state_color_2000_district, join_by("STATENAME"=="state"))# Plot of Alaska with colors corresponding to the parties (Democrat = Blue, Republican = Red)alaska_plot_district <- alaska_colors_district |>st_shift_longitude() |>ggplot(aes(geometry = geometry,fill = candidate_last)) +geom_sf() +scale_fill_manual(values =c("Gore"="royalblue1", "Bush"="tomato")) +coord_sf(xlim =c(170, 250)) +theme_void() +guides(fill =FALSE)# Filtering only for Hawaiihawaii_district <- districts_107_sf |>filter(STATENAME =="Hawaii")# Merging the two tables (alaska and state_color_2000) so we know which party won the election for Alaskahawaii_colors_district <-left_join(hawaii_district, state_color_2000_district, join_by("STATENAME"=="state"))# Plot of Hawaii with colors corresponding to the parties (Democrat = Blue, Republican = Red)hawaii_plot_district <- hawaii_colors_district |>ggplot(aes(geometry = geometry,fill = candidate_last)) +geom_sf() +scale_fill_manual(values =c("Gore"="royalblue1", "Bush"="tomato")) +labs(x =NULL, y =NULL) +theme_void() +guides(fill =FALSE)
Lastly, here is the code that puts all three of our plots together onto one plot for easy viewing.
Code
# Combined mainland plot with insetted elements Alaska and Hawaii plots on the lower leftmainland_plot_district +inset_element(hawaii_plot_district, 0, 0, 0.3, 0.3) +inset_element(alaska_plot_district, 0, 0, 0.2, 0.4)
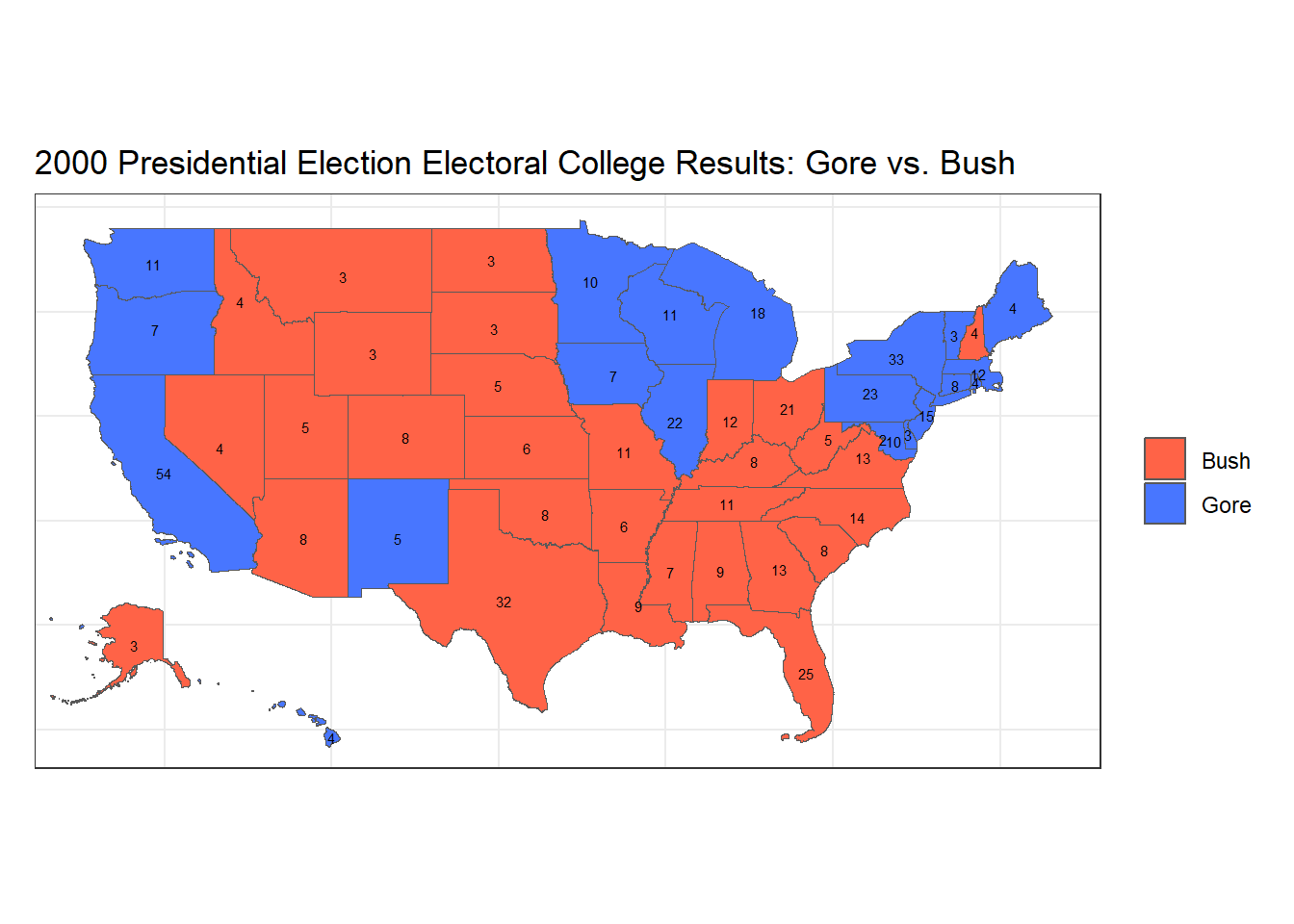
To avoid the overwhelming lines on top of the map, we can use a state shape file to more easily visualize the state outlines without having the district outlines. Below is another choropleth map with the same coloring that includes only the shape outlines and also the ECV counts for each state. The same process from above is repeated to inset Hawaii and Alaska onto our map for easier viewing.
Code
# Selecting only state and party_simplified columns to simplify when joining with sfstate_color <- winner_election_2000 |>select(state, candidate, party_simplified) |>mutate(candidate_last =case_when(candidate =="BUSH, GEORGE W."~"Bush",candidate =="GORE, AL"~"Gore"))# Adding the respective ECV count for each state in 2000# Data frame with ECV count from 2000ecv_per_state_2000_no_dc <- house_1976_2022 |>select(c(year, state, district)) |>unique() |>filter(year ==2000) |>group_by(state) |>summarize(total =n()) |>mutate(ecv_total = total +2) |>select(-c(total))# Adding DC's 2 ECVs for that election --> One Democratic elector abstained from casting a voteecv_per_state_2000 <-rbind(ecv_per_state_2000_no_dc, data.frame(state ="DISTRICT OF COLUMBIA", ecv_total =2))# Merging data frame state_color with ecv countsstate_color_ecv <-left_join(state_color, ecv_per_state_2000, by ="state")# Filtering only for states in the mainland so our plot isn't squished, also filtering out places that aren't in the 50 statesmainland <- state_2020_sf |>filter(!(NAME %in%c("Alaska", "Hawaii", "United States Virgin Islands", "Commonwealth of the Northern Mariana Islands", "Guam", "American Samoa", "Puerto Rico"))) |>mutate(NAME =toupper(NAME))# Merging the two tables so we know which party won the election for each statemainland_colors <-left_join(mainland, state_color_ecv, join_by("NAME"=="state"))# Plot of mainland with colors corresponding to the parties (Democrat = Blue, Republican = Red)mainland_plot <- mainland_colors |>ggplot(aes(geometry = geometry,fill = candidate_last)) +geom_sf() +geom_sf_text(aes(label = ecv_total), color ="black", size =2) +scale_fill_manual(values =c("Gore"="royalblue1", "Bush"="tomato")) +theme_bw() +theme(legend.title =element_blank(),axis.title.x=element_blank(),axis.text.x=element_blank(),axis.ticks.x=element_blank(),axis.title.y=element_blank(),axis.text.y=element_blank(),axis.ticks.y=element_blank()) +labs(title ="2000 Presidential Election Electoral College Results: Gore vs. Bush")
Code
# Filtering only for Alaskaalaska <- state_2020_sf |>filter(NAME =="Alaska") |>mutate(NAME =toupper(NAME))# Merging the two tables (alaska and state_color_2000) so we know which party won the election for Alaskaalaska_colors <-left_join(alaska, state_color_ecv, join_by("NAME"=="state"))# Plot of Alaska with colors corresponding to the parties (Democrat = Blue, Republican = Red)alaska_plot <- alaska_colors |>st_shift_longitude() |>ggplot(aes(geometry = geometry,fill = candidate_last)) +geom_sf() +geom_sf_text(aes(label = ecv_total), color ="black", size =2) +scale_fill_manual(values =c("Gore"="royalblue1", "Bush"="tomato")) +coord_sf(xlim =c(170, 250)) +theme_void() +guides(fill =FALSE)# Filtering only for Hawaiihawaii <- state_2020_sf |>filter(NAME =="Hawaii") |>mutate(NAME =toupper(NAME))# Merging the two tables (alaska and state_color_2000) so we know which party won the election for Alaskahawaii_colors <-left_join(hawaii, state_color_ecv, join_by("NAME"=="state"))# Plot of Hawaii with colors corresponding to the parties (Democrat = Blue, Republican = Red)hawaii_plot <- hawaii_colors |>ggplot(aes(geometry = geometry,fill = candidate_last)) +geom_sf() +geom_sf_text(aes(label = ecv_total), color ="black", size =2) +scale_fill_manual(values =c("Gore"="royalblue1", "Bush"="tomato")) +labs(x =NULL, y =NULL) +theme_void() +guides(fill =FALSE)
# Count the total ECVs per candidate to confirm the winner of the 2000 Presidential Electionwinner_2000 <- state_color_ecv |>group_by(candidate_last) |>summarize(ecv =sum(ecv_total))# Pull the last name of the candidate that won the 2000 Election -- Bushwinner_2000_name <- winner_2000 |>slice_max(ecv, n =1) |>pull(candidate_last)# Pull the total ECVs the winning candidate received in the 2000 Election -- 271winner_2000_count <- winner_2000 |>slice_max(ecv, n =1) |>pull(ecv)# Pull total ECVs of the losing candidate from the 2000 Election -- 266loser_2000_count <- winner_2000 |>slice_min(ecv, n =1) |>pull(ecv)
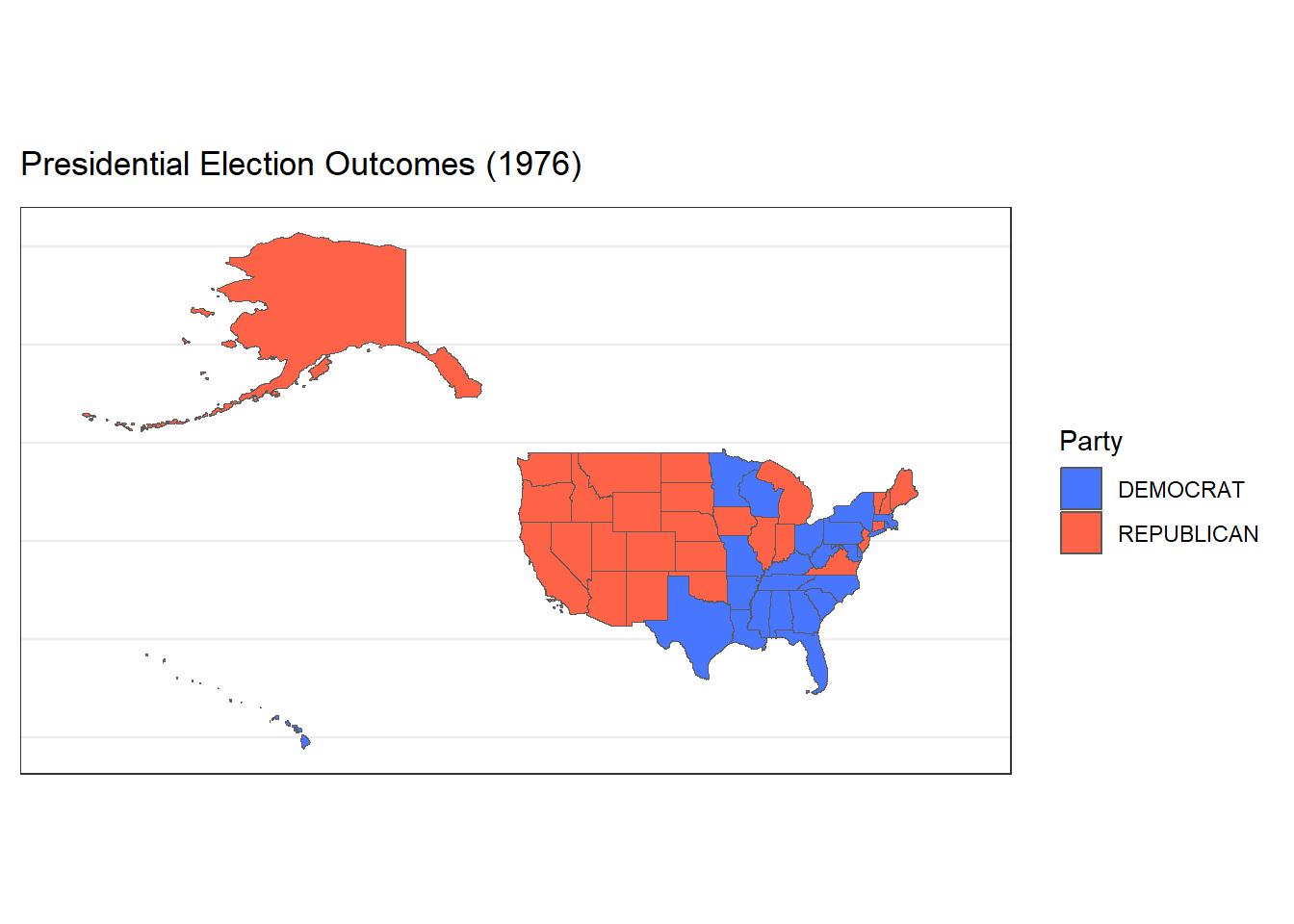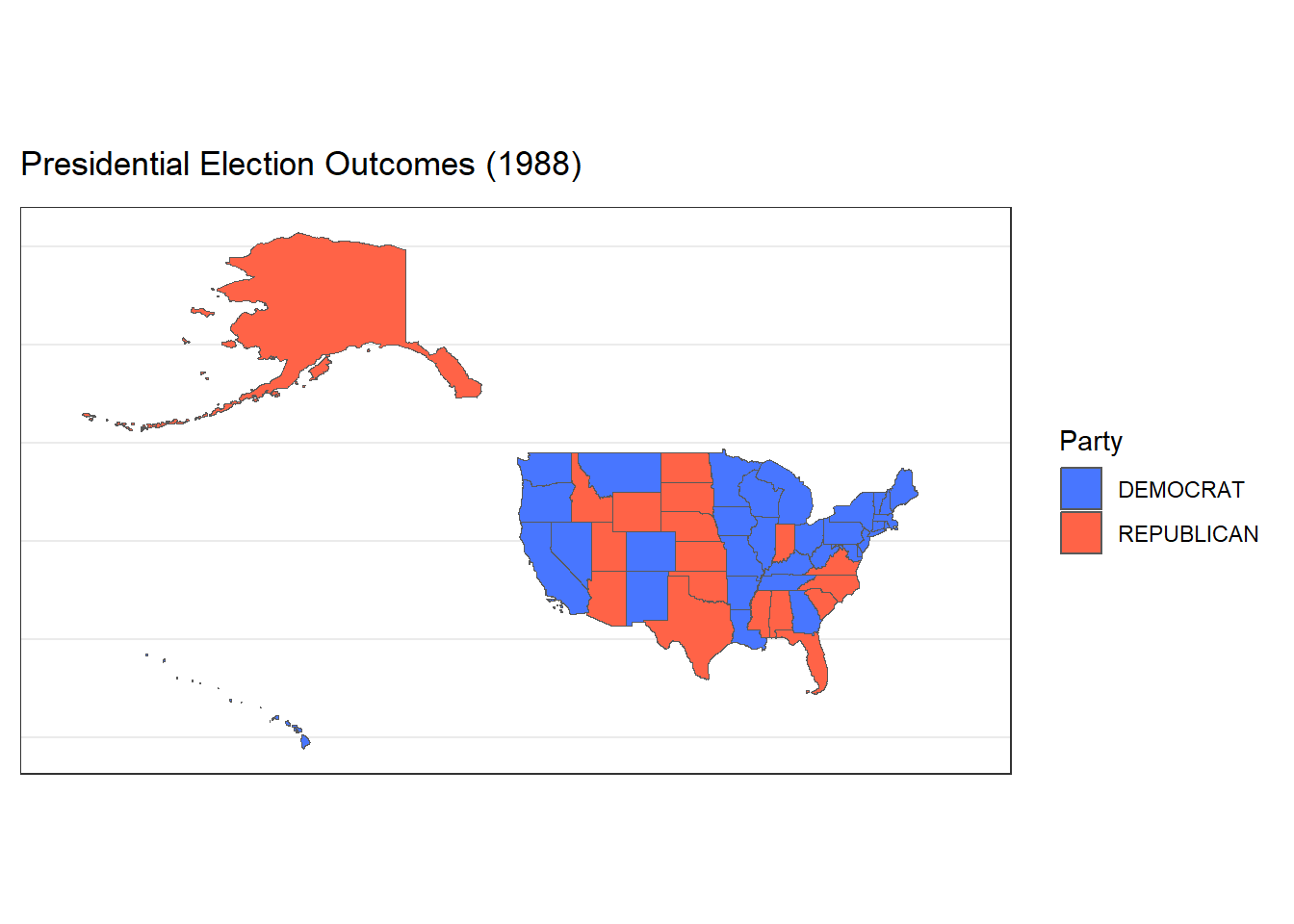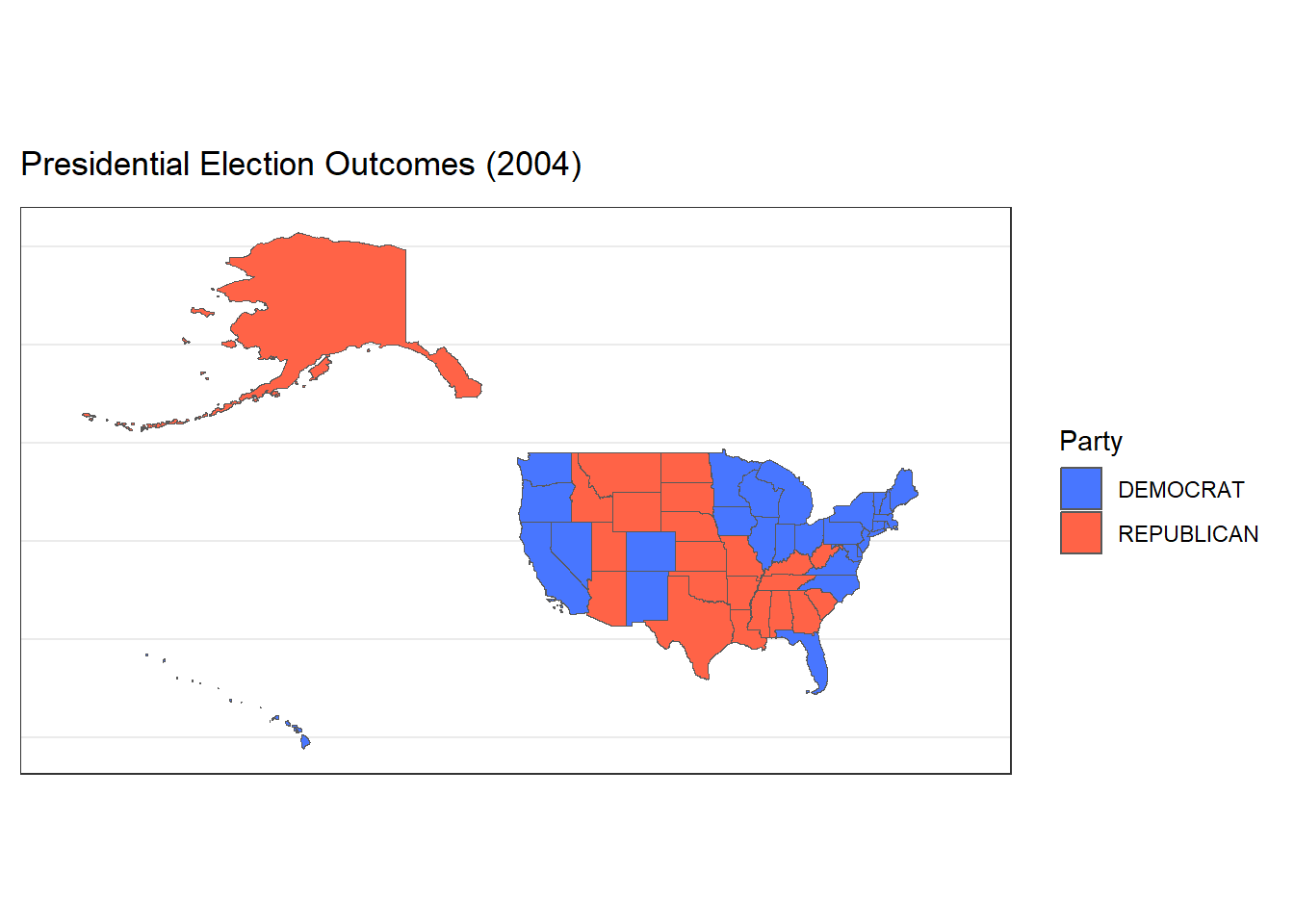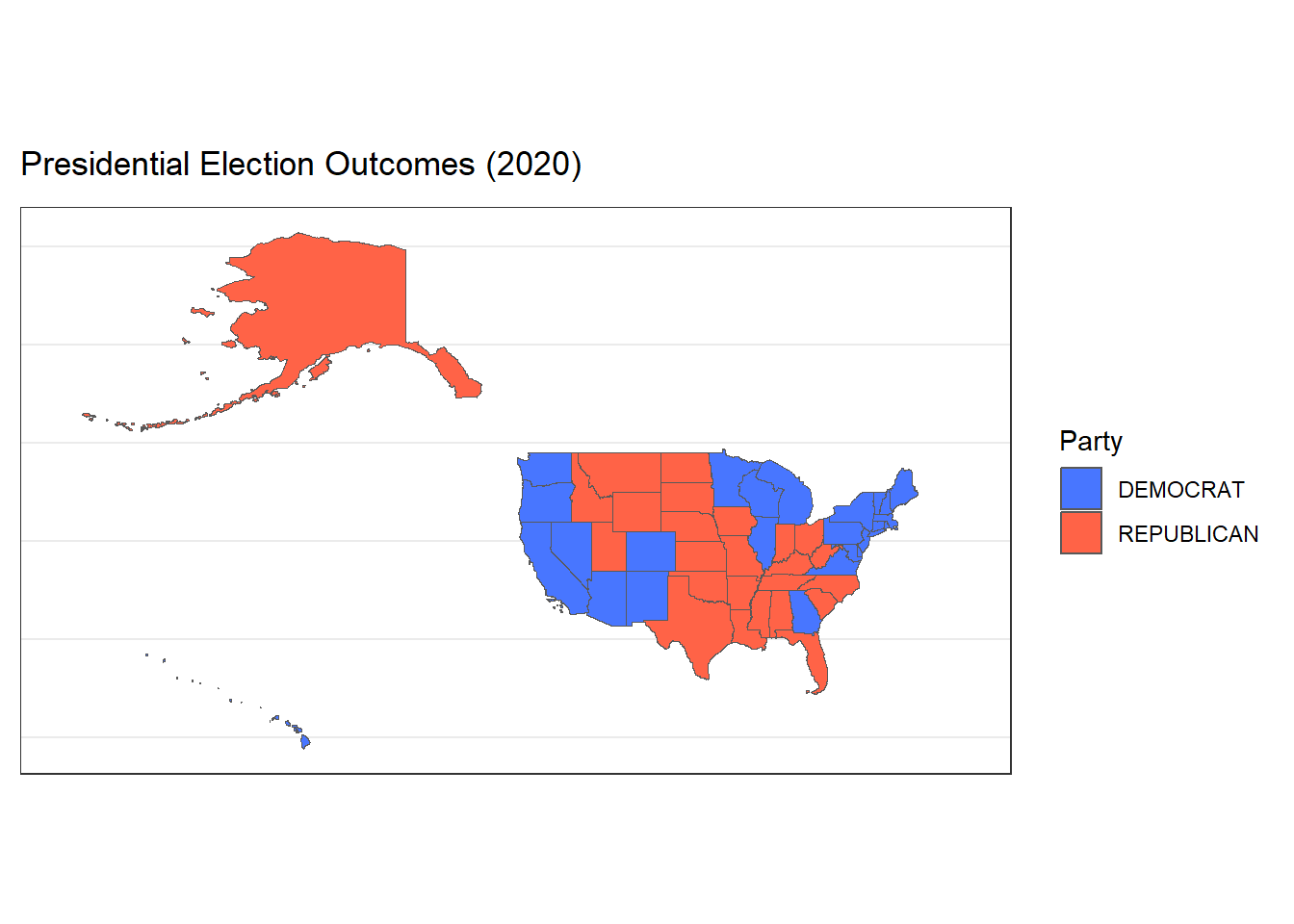
From our new choropleth plot above, there is a clearer indication of state lines as well as the ECVs allocated per state. At first glance without these ECVs, it seems as though a large majority of the map is colored red, for George W. Bush. Taking a closer look at the total ECV count for each candidate, we find that ultimately Bush won the election by a slim margin, 271 ECVs to Al Gore’s 266.
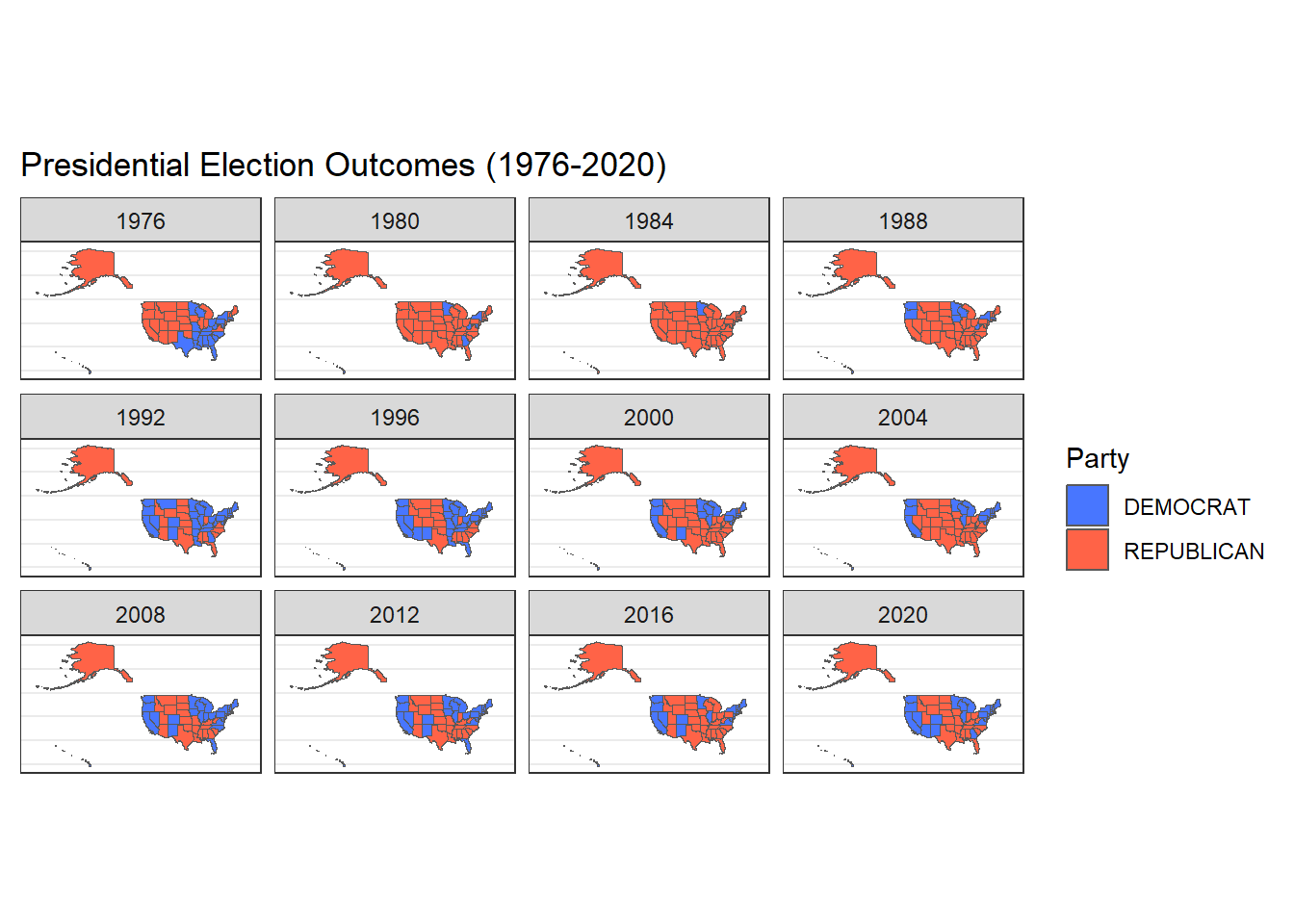
Faceted and Animated Plots Presidental Elections (1976-2020)
Now let’s expand our findings beyond the 2000 presidential election to all the presidential elections from 1976-2020. We could do so with a faceted plot shown below. Each facet represents one of 12 presidential elections that occurred between this time period. It is interesting to visualize the changes in voting patterns for certain states over time.
Code
# Data frame with the winner for each state in each electionwinner_each_election_per_state <- president_1976_2020 |>filter(party_simplified %in%c("DEMOCRAT", "REPUBLICAN")) |>group_by(year, state) |>mutate(most_votes =max(candidatevotes)) |>ungroup() |>mutate(win = (candidatevotes == most_votes),winner =case_when(win ==TRUE~ candidate)) |>drop_na(winner)# Change the case of the states column in our state shape filestate_2020_sf_case <- state_2020_sf |>filter(!(NAME %in%c("United States Virgin Islands", "Commonwealth of the Northern Mariana Islands", "Guam", "American Samoa", "Puerto Rico"))) |>mutate(NAME =toupper(NAME))# Data frame merging the winner from each state in each election with the shape filewinner_colors <-left_join(state_2020_sf_case, winner_each_election_per_state, join_by("NAME"=="state"))
Additionally, I added an animated version of the plots to demonstrate the election results over time. Each animated state of the plot is a different election, demonstrating how some states have changed their voting patterns over time.
Currently, electoral college votes are allocated in a state-wide winner-take-all fashion for 48 states and the District of Columbia. For the remaining two states, Nebraska and Maine, a district-wide winner-take-all + state-wide “at large” votes strategy is utilized. Throughout the course of history, various strategies have been used. This begs the question if election results would have been significantly different if all states used different ECV allocation rules.
Lastly, we will be taking a look at the various ECV allocation strategies to determine if any significant election changes would have occurred with alternative methods. We will be allocating ECVs with the following strategies:
# Data frame that counts the ECV for each state each yearecv_per_state_per_year <- house_1976_2022 |>select(c(year, state, district)) |>unique() |>group_by(year, state) |>summarize(total =n()) |>mutate(ecv_total = total +2) |>select(-c("total")) |>ungroup()# Only 2020 includes DC's 3 ECVs, so we needto include DC's 3 votes for the other electionsecv_per_state_per_year <- ecv_per_state_per_year |>add_row(year =1976, state ="DISTRICT OF COLUMBIA", ecv_total =3) |>add_row(year =1980, state ="DISTRICT OF COLUMBIA", ecv_total =3) |>add_row(year =1984, state ="DISTRICT OF COLUMBIA", ecv_total =3) |>add_row(year =1988, state ="DISTRICT OF COLUMBIA", ecv_total =3) |>add_row(year =1992, state ="DISTRICT OF COLUMBIA", ecv_total =3) |>add_row(year =1996, state ="DISTRICT OF COLUMBIA", ecv_total =3) |>add_row(year =2000, state ="DISTRICT OF COLUMBIA", ecv_total =3) |>add_row(year =2004, state ="DISTRICT OF COLUMBIA", ecv_total =3) |>add_row(year =2008, state ="DISTRICT OF COLUMBIA", ecv_total =3) |>add_row(year =2012, state ="DISTRICT OF COLUMBIA", ecv_total =3) |>add_row(year =2016, state ="DISTRICT OF COLUMBIA", ecv_total =3) |>add_row(year =2020, state ="DISTRICT OF COLUMBIA", ecv_total =3) |>distinct()
State-Wide Winner-Take-All
Below is the results of the election with an ECV allocation method of State-Wide Winner-Take-All, where the winner of the popular vote for each states wins all ECVs for that respective state. This is essentially what our country currently has in place and reflects the results of the elections from 1976-2020.
Code
# Create a new data frame that groups by calculates the winner of each state's presidential election in a state-wide winner-take-all formatstate_wide_winner_take_all <- president_1976_2020 |>group_by(year, state, candidate) |>summarize(total_votes =sum(candidatevotes)) |>filter(total_votes ==max(total_votes)) |>ungroup()# Include the candidate's partiescandidate_party <- president_1976_2020 |>select(year, state, candidate, party_simplified) |>filter(party_simplified %in%c("DEMOCRAT", "REPUBLICAN")) |>rename(party = party_simplified)# Merge first two tables so we have the candidate and the respective main partystate_wide_winner_take_all_results <-left_join(state_wide_winner_take_all, candidate_party, by =c("year", "state", "candidate"))# Merging data frame with the ECV counts for each yearecv_state_wide_winner <-left_join(state_wide_winner_take_all_results, ecv_per_state_per_year, by =c('year', 'state'))# Data frame containing the winner of each election by majority ECVselection_winner_state_wide <- ecv_state_wide_winner |>group_by(year, candidate, party) |>drop_na(ecv_total) |>summarize(results =sum(ecv_total)) |>ungroup() |>group_by(year) |>filter(results ==max(results)) |>ungroup() |>rename(state_wide_winner = candidate,state_wide_party = party,state_wide_results = results)# Display TableDT::datatable(setNames(election_winner_state_wide, c("Year", "Winner", "Party", "Electoral College Votes")),caption ="Table 3: State-Wide Winner-Take-All Election Winners",rownames =FALSE,options =list(pageLength =12))
Next, we will take a look at the District-Wide Winner-Take-All + State-Wide “At Large” Votes ECV allocation method. This is a relatively complex allocation strategy which counts the ECVs for candidates based on the party winner of congressional district elections, then the remaining 2 ECVs for each state are allocated based on the state popular vote winner. Below is the data frame showing the election winners had this method been applied for each state in each election.
Code
# Data frame counting ECV for each state based on party winner from congressional district votingwinner_per_district_per_year <- house_1976_2022 |>group_by(year, state, district) |>filter(candidatevotes ==max(candidatevotes)) |>select(year, state, district, party) |>ungroup() |>group_by(year, state, party) |>summarize(ecv_count =n())# Data frame with candidate and respective partycandidate_party <- president_1976_2020 |>select(year, state, candidate, party_simplified) |>filter(party_simplified %in%c("DEMOCRAT", "REPUBLICAN")) |>rename(party = party_simplified)# Merge the two data frames, so we can properly tally up the votes for each candidate each election yearmerge_district_ecv_count <-left_join(winner_per_district_per_year, candidate_party, by =c("year", "state", "party")) |>drop_na(candidate)# Need the statewide popular vote winner to allocate the remaining 2 ECVs can use data frame from the previous section ... ecv_state_wide_winner data framestate_wide_popular <- ecv_state_wide_winner |>select(year, state, candidate, party) |>rename(state_winner = candidate,state_winner_party = party)# Merge data frame with our other data frame to include the extra 2 ECVs for the statewide popular vote winner, then find the majority winner by ECVelection_winner_district_wide <-left_join(merge_district_ecv_count, state_wide_popular, by =c('year', 'state')) |>mutate(ecv_extra =case_when(candidate == state_winner ~2, candidate != state_winner ~0),ecv_total = ecv_count + ecv_extra) |>group_by(year, candidate, party) |>summarize(candidate_ecv_total =sum(ecv_total)) |>drop_na(candidate) |>ungroup() |>group_by(year) |>filter(candidate_ecv_total ==max(candidate_ecv_total)) |>ungroup() |>rename(district_wide_winner = candidate,district_wide_party = party,district_wide_results = candidate_ecv_total)DT::datatable(setNames(election_winner_district_wide, c("Year", "Winner", "Party", "Electoral College Votes")),caption ="Table 4: District-Wide Winner-Take-All + State-Wide 'At Large' Votes Election Winners",rownames =FALSE,options =list(pageLength =12))
State-Wide Proportional
Another ECV allocation method is taking the proportion of candidate votes for each party in each state and allocating the state’s ECV appropriately. For instance, if Candidate A received 200,000 votes and Candidate B received 300,000 votes for State C, then Candidate A would be allocated 40% of the ECVs for the state while Candidate B receives 60% of the ECvs for State C. The same is repeated for all 50 states. Then the candidate with the most ECVs would win the election. The data table below reveals the winners had the election utilized a State-Wide Proportional ECV allocation strategy.
Code
# Data frame including the proportion of votes each candidate earned from each statestate_wide_proportional <- president_1976_2020 |>mutate(prop = candidatevotes / totalvotes)# Merging above data frame with the ECV counts for each yearecv_state_proportion_winner <-left_join(state_wide_proportional, ecv_per_state_per_year, by =c('year', 'state'))# Data frame with winner after calculating the proportionate ECV per stateelection_winner_state_prop <- ecv_state_proportion_winner |>select(year, state, candidate, party_simplified, prop, ecv_total) |>mutate(ecv_votes =round(prop * ecv_total)) |>filter(ecv_votes !=0) |>group_by(year, candidate, party_simplified) |>summarize(combined_ecv =sum(ecv_votes)) |>ungroup() |>group_by(year) |>filter(combined_ecv ==max(combined_ecv)) |>ungroup() |>rename(state_prop_winner = candidate,state_prop_party = party_simplified,state_prop_results = combined_ecv)# Display TableDT::datatable(setNames(election_winner_state_prop, c("Year", "Winner", "Party", "Electoral College Votes")), caption ="Table 5: State-Wide Proportional Election Winner",rownames =FALSE,options =list(pageLength =12))
National Proportional
Lastly, we have the National Proportional ECV allocation method, which acts similar to the State-Wide Proportional method, but on a nation-wide scale. We take the proportion of nation-wide popular votes for each candidate then allocate ECVs based on these holistic values. The data frame below shows the results of each election if a National Proportional ECV allocation was used.
Code
# Data frame including the proportion of votes each candidate earned from the entire nationnation_wide_proportional <- president_1976_2020 |>group_by(year, candidate, party_simplified) |>summarize(candidate_total =sum(candidatevotes)) |>ungroup() |>group_by(year) |>mutate(total_year =sum(candidate_total),prop = candidate_total / total_year) |>ungroup()# Data frame with the total ECV per yeartotal_ecv_per_year <- ecv_per_state_per_year |>group_by(year) |>summarize(total_ecv =sum(ecv_total))# Merge data framesmerge_nation_wide_ecv <-left_join(nation_wide_proportional, total_ecv_per_year, by =c('year'))# Data frame with winner after calculating proportional ECV nation wideelection_winner_nation_prop <- merge_nation_wide_ecv |>mutate(combined_ecv =round(prop * total_ecv)) |>filter(combined_ecv !=0) |>group_by(year) |>filter(combined_ecv ==max(combined_ecv)) |>ungroup() |>select(year, candidate, party_simplified, combined_ecv) |>rename(nation_prop_winner = candidate,nation_prop_party = party_simplified,nation_prop_results = combined_ecv)DT::datatable(setNames(election_winner_nation_prop, c("Year", "Winner", "Party", "Electoral College Votes")), caption ="Table 6: National Proportional Election Winner",rownames =FALSE,options =list(pageLength =12))
Below is a data frame that combines the results of all the possible election outcomes for easier comparison.
Code
# Merge all 4 results tables together into one data table with all the aggregated informationcombined_results <-left_join(election_winner_state_wide, election_winner_district_wide, by ="year") |>left_join(election_winner_state_prop, by ="year") |>left_join(election_winner_nation_prop, by ="year")
Here are the potential US presidents for elections between 1976 and 2020 had each election’s ECV allocation been different.
Code
# Filter only for the candidatescombined_results |>select(year, state_wide_winner, district_wide_winner, state_prop_winner, nation_prop_winner) |>rename(Year = year,`State Wide`= state_wide_winner,`District Wide`= district_wide_winner,`State Proportional`= state_prop_winner,`National Proportional`= nation_prop_winner) |> DT::datatable(caption ="Table 7: Election Winners for Different ECV Allocation Schemes",rownames =FALSE,options =list(pageLength =12))
From first glance, the election results didn’t seem too different from the actual outcomes (using the State Wide column). We can observe that for the district allocation method, election outcomes were different for the years 1988, with Michael Dukakis, and 2012, with Mitt Romney, as the winners. In the state-wide proportional voting, the only difference we observe is that Hillary Clinton would have won the 2016 election. Lastly, with the national proportion method, we have that Al Gore and Hillary Clinton would have won the 2000 and 2016 elections, respectively.
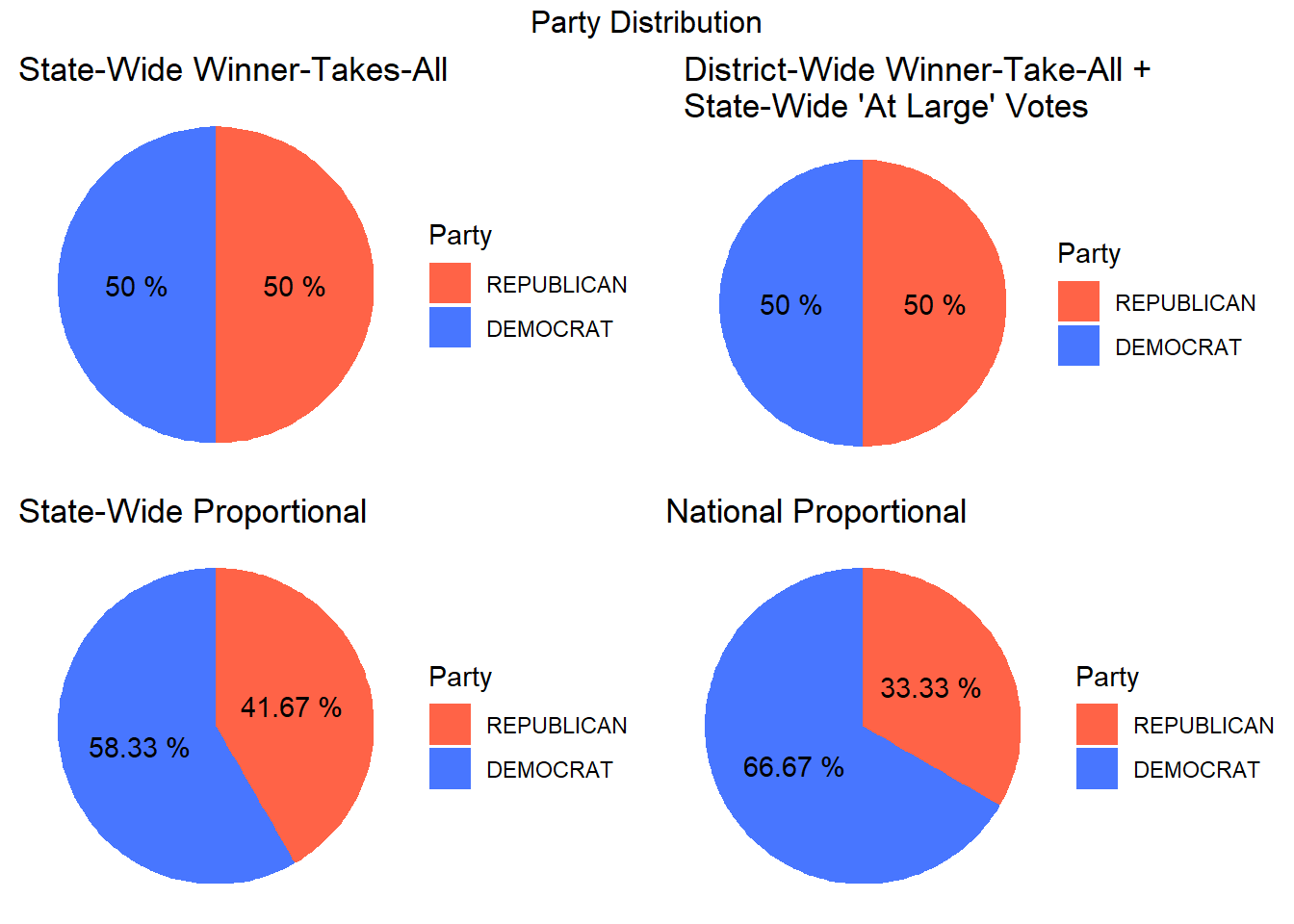
Next, we would like to take a look at whether certain ECV allocation schemes seem to favor certain parties. Below are pie charts showing the distribution of party outcomes for each allocation method.
In our above pie charts, we find that both of the proportional schemes (state-wide proportional and national proportional) seem to favor the Democratic party over the Republican Party, while the remaining two methods (state-wide winner-takes-all and district-wide winner-take-all + state-wide “at large” votes) seem balanced with a perfect 50/50 split between the two parties. Despite the national proportional method and state-wide proportional method seemingly favoring the Democratic Party, these methods provide a better representation of the voting population, valuing each vote more closely than the other methods, which could perhaps suggest that this is reflective of the nation’s voter preferences.
Final Thoughts
Various elections would have been different had the electoral college vote allocations. Two examples are the 2000 election and the 2016 election. In the 2000 election, Al Gore won the popular vote and would have won with the national proportional voting scheme but lost in every other method. For the 2016 election, Hillary Clinton also won the national popular vote and would have won with a state-wide proportional vote as well. This leads to the question of fairness among these different allocation schemes.
Each of the four electoral college vote allocation schemes has its strengths and weaknesses, I will be evaluating the “fairness” of each of these methods below.
Among all four options, I believe that the “fairest” ECV allocation method would be the national proportional scheme. The national proportional method takes everyone’s vote into consideration when allocating the electoral college votes. In the past, there have been elections where candidates have won the popular vote (gained the most votes among all US voters), but because of the state-wide winner-take-all allocation scheme, these candidates are left with fewer ECVs and thus, lose the election. The National Proportional allocation scheme would highly reflect voter preferences by allowing the majority popular vote winner to take office. However, to implement this scheme, every state would have to agree to implement this strategy and it may require a change in the Constitution.
Next, I believe that the state-wide proportional ECV allocation strategy would be the next “fairest” allocation scheme. Similar to the national proportional method, the state-wide proportional method values each person’s vote equally per state. In this scheme, presidential candidates would get votes according to their state-level popularity. Additionally, the impact of swing states would be reduced, rather than a few hundred thousands of votes determining an election, more of an emphasis would be placed on individuals’ votes in each state. As compared to the national proportional vote, the state-wide proportional vote would reflect voter preferences from the respective state, however, since each state may have a different number of ECVs, some people’s votes may weigh less than others in the grand scheme. Implementing the state-wide proportional ECV still would require a state to make legislative changes, but would not be as tedious as what is required in the national proportional method.
Of the remaining two allocation methods, I believe the district-wide winner-take-all + state-wide “at large” votes would be the next fairest scheme. This method takes the state-wide proportional method a step further by allocating each ECV by the popular vote winner of the respective district, which can better represent a state’s diversity of voting preferences compared to the state-wide winner-take-all method. This method similar to the above two will reduce the chances of candidates winning the popular vote but losing the electoral college, as we saw in some of the past elections. However, with this method of ECV allocation, a possible issue could occur with the bounds of districts (gerrymandering), if certain districts are changed, certain parties may be favored over others, which could skew the outcome of the election.
Lastly, in my opinion, the state-wide winner-take-all approach takes last in the “fairest” rankings. This allocation method only values the votes of the majority of the population in a state, and does not reflect the larger popular vote representation of an entire nation let alone one state. This is especially apparent in swing states, where elections come down to hundreds or even tens of thousands of votes, in which case the candidate that edges out obtains all ECVs. Ultimately, while this ECV allocation method is the simplest to implement, it often does not reflect voter preferences, making it the least “fairest” strategy.
Footnotes
MIT Election Data + Science Lab. (n.d.). MIT Election Lab. MIT Election Data + Science Lab. https://electionlab.mit.edu/↩︎